Angr简介 Angr提供了一个处理二进制文件的框架 主流的指令集指令在被载入CLE框架后 会根据功能被抽象为中间语言(IL) Angr提供的就是处理这些被载入为IL的程序 可以用来实现自动化的程序调试 例如直接载入程序然后像模拟的标准输入流输入数据以达到直接利用原程序进行爆破的目的 同时Angr还内置了约束求解器
做做题 下面跟着Angr-ctf 里的题目学习Angr的基础应用
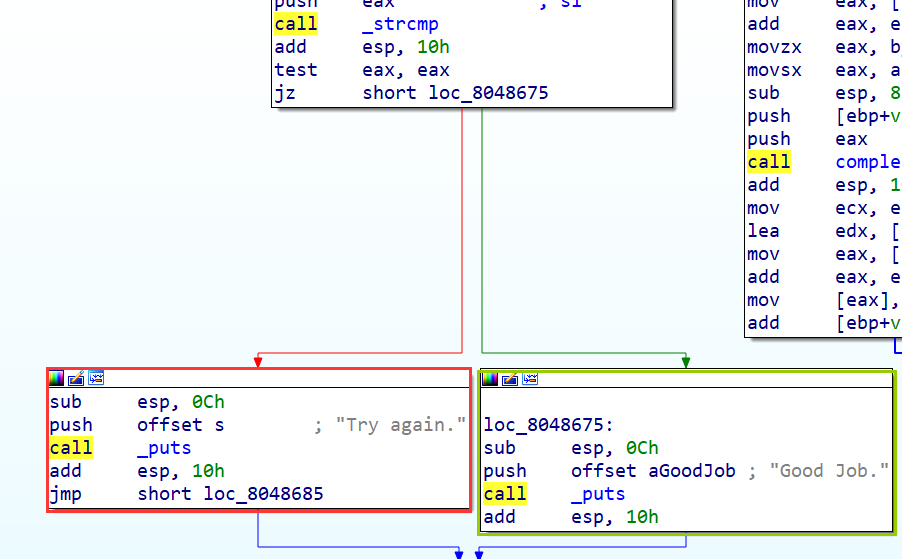
angr_find IDA加载附件看一下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 int __cdecl complex_function (int a1, int a2) { if ( a1 <= 64 || a1 > 90 ) { puts ("Try again." ); exit (1 ); } return (3 * a2 + a1 - 65 ) % 26 + 65 ; } int __cdecl main (int argc, const char **argv, const char **envp) { int i; char s1[9 ]; unsigned int v6; v6 = __readgsdword(0x14 u); printf ("Enter the password: " ); __isoc99_scanf("%8s" , s1); for ( i = 0 ; i <= 7 ; ++i ) s1[i] = complex_function(s1[i], i); if ( !strcmp (s1, "JACEJGCS" ) ) puts ("Good Job." ); else puts ("Try again." ); return 0 ; }
显然目标是要进入输出”Good Job.”的分支
用angr爆破:
1 2 3 4 5 6 7 8 9 10 11 12 import angrproj = angr.Project('00_angr_find' , load_options={'auto_load_libs' : False }) state = proj.factory.entry_state() simg = proj.factory.simgr(state) simg.explore(find=0x8048675 , avoid=0x8048663 ) print (simg.found[0 ].posix.dumps(0 ))
angr_find_condition 主函数进行了混淆 加入了很多实际上控制流不会经过的块 不过还好IDA的反汇编功能比较强大 伪代码看起来还是很清晰的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 int __cdecl main (int argc, const char **argv, const char **envp) { int i; int j; char s1[20 ]; char s2[20 ]; unsigned int v8; v8 = __readgsdword(0x14 u); for ( i = 0 ; i <= 19 ; ++i ) s2[i] = 0 ; qmemcpy(s2, "VXRRJEUR" , 8 ); printf ("Enter the password: " ); __isoc99_scanf("%8s" , s1); for ( j = 0 ; j <= 7 ; ++j ) s1[j] = complex_function(s1[j], j + 8 ); if ( !strcmp (s1, s2) ) puts ("Good Job." ); else puts ("Try again." ); return 0 ; }
整体逻辑和前面的题基本相同 引入新的爆破方法 顺便借机研究以下angr执行的模式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import angr, syseip_record = [] branch_record = [] def is_succ (state ): eip = state.regs.eip.args[0 ] if eip not in eip_record: eip_record.append(eip) elif eip not in branch_record: branch_record.append(eip) print ('EIP:' , hex (eip)[2 :]) return b'Good Job' in state.posix.dumps(1 ) def is_fail (state ): eip = state.regs.eip.args[0 ] return b'Try again' in state.posix.dumps(1 ) def main (argv ): proj = angr.Project('02_angr_find_condition' , load_options={'auto_load_libs' :False }) simstate = proj.factory.entry_state() simmgr = proj.factory.simgr(simstate) simmgr.explore(find=is_succ, avoid=is_fail) if simmgr.found: print (simmgr.found[0 ].posix.dumps(0 )) if __name__ == '__main__' : main(sys.argv)
去掉注释再执行可以看到实际上.explore函数每次执行is_succ的检测同时会执行is_fail 而每组执行的两个检测传入的state包含了相同(? 至少EIP相同)的运行状态 那么来看看每次执行的时候EIP执行到了哪里
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 EIP: 8048450 EIP: 8048420 EIP: 8100014 EIP: 804d290 WARNING | 2024-07-19 15:11:59,957 | angr.storage.memory_mixins.default_filler_mixin | The program is accessing register with an unspecified value. This could indicate unwanted behavior. WARNING | 2024-07-19 15:11:59,959 | angr.storage.memory_mixins.default_filler_mixin | angr will cope with this by generating an unconstrained symbolic variable and continuing. You can resolve this by: WARNING | 2024-07-19 15:11:59,959 | angr.storage.memory_mixins.default_filler_mixin | 1) setting a value to the initial state WARNING | 2024-07-19 15:11:59,959 | angr.storage.memory_mixins.default_filler_mixin | 2) adding the state option ZERO_FILL_UNCONSTRAINED_{MEMORY,REGISTERS}, to make unknown regions hold null WARNING | 2024-07-19 15:11:59,959 | angr.storage.memory_mixins.default_filler_mixin | 3) adding the state option SYMBOL_FILL_UNCONSTRAINED_{MEMORY,REGISTERS}, to suppress these messages. WARNING | 2024-07-19 15:11:59,959 | angr.storage.memory_mixins.default_filler_mixin | Filling register edi with 4 unconstrained bytes referenced from 0x804d291 (__libc_csu_init+0x1 in 02_angr_find_condition (0x804d291)) WARNING | 2024-07-19 15:11:59,959 | angr.storage.memory_mixins.default_filler_mixin | Filling register ebx with 4 unconstrained bytes referenced from 0x804d293 (__libc_csu_init+0x3 in 02_angr_find_condition (0x804d293)) EIP: 8048480 EIP: 804d299 EIP: 8048394 EIP: 8048480 EIP: 804839d EIP: 80483b2 EIP: 804d2b1 EIP: 804d2c0 EIP: 8048520 EIP: 804852b EIP: 80484c0 EIP: 80484f3 EIP: 804d2db EIP: 804d2e5 EIP: 820104c EIP: 80485c8 EIP: 804860b EIP: 80485fc EIP: 80485fc EIP: 80485fc EIP: 80485fc EIP: 80485fc EIP: 80485fc EIP: 80485fc EIP: 80485fc EIP: 80485fc EIP: 80485fc EIP: 80485fc EIP: 80485fc EIP: 80485fc EIP: 80485fc EIP: 80485fc EIP: 80485fc EIP: 80485fc EIP: 80485fc EIP: 80485fc EIP: 80485fc EIP: 8048611 EIP: 80483e0 EIP: 8100004 EIP: 804862e EIP: 8048430 EIP: 8100018 EIP: 8048642 EIP: 804867f EIP: 804864e EIP: 8048569 EIP: 804857b EIP: 8048575 EIP: 8048400 EIP: 8048595 EIP: 804857b EIP: 810000c EIP: 804866c EIP: 8048400 EIP: 8048588 EIP: 804864e EIP: 810000c EIP: 8048569 EIP: 8048588 EIP: 804857b EIP: 8048575 EIP: 8048400 EIP: 8048595 EIP: 804857b EIP: 810000c EIP: 804866c EIP: 8048400 EIP: 8048588 EIP: 804864e EIP: 810000c EIP: 8048569 EIP: 8048588 EIP: 804857b EIP: 8048575 EIP: 8048400 EIP: 8048595 EIP: 804857b EIP: 810000c EIP: 804866c EIP: 8048400 EIP: 8048588 EIP: 804864e EIP: 810000c EIP: 8048569 EIP: 8048588 EIP: 804857b EIP: 8048575 EIP: 8048400 EIP: 8048595 EIP: 804857b EIP: 810000c EIP: 804866c EIP: 8048400 EIP: 8048588 EIP: 804864e EIP: 810000c EIP: 8048569 EIP: 8048588 EIP: 804857b EIP: 8048575 EIP: 8048400 EIP: 8048595 EIP: 804857b EIP: 810000c EIP: 804866c EIP: 8048400 EIP: 8048588 EIP: 804864e EIP: 810000c EIP: 8048569 EIP: 8048588 EIP: 804857b EIP: 8048575 EIP: 8048400 EIP: 8048595 EIP: 804857b EIP: 810000c EIP: 804866c EIP: 8048400 EIP: 8048588 EIP: 804864e EIP: 810000c EIP: 8048569 EIP: 8048588 EIP: 804857b EIP: 8048575 EIP: 8048400 EIP: 8048595 EIP: 804857b EIP: 810000c EIP: 804866c EIP: 8048400 EIP: 8048588 EIP: 804864e EIP: 810000c EIP: 8048569 EIP: 8048588 EIP: 804857b EIP: 8048575 EIP: 8048400 EIP: 8048595 EIP: 804857b EIP: 810000c EIP: 804866c EIP: 8048400 EIP: 8048588 EIP: 8048685 EIP: 810000c EIP: 8048692 EIP: 8048588 EIP: 804869f EIP: 80486ac EIP: 8048b6c EIP: 8048dcc EIP: 8048efc EIP: 8048f94 EIP: 8048fde EIP: 80483d0 EIP: 8100000 WARNING | 2024-07-19 15:12:01,375 | angr.storage.memory_mixins.default_filler_mixin | Filling memory at 0x7ffeff2d with 11 unconstrained bytes referenced from 0x8100000 (strcmp+0x0 in extern-address space (0x0)) WARNING | 2024-07-19 15:12:01,379 | angr.storage.memory_mixins.default_filler_mixin | Filling memory at 0x7ffeff50 with 4 unconstrained bytes referenced from 0x8100000 (strcmp+0x0 in extern-address space (0x0)) EIP: 8048fee EIP: 804900a EIP: 8048ff5 EIP: 8048400 EIP: 8048400 EIP: 810000c EIP: 810000c EIP: 8049017 EIP: 8049002 b'HETOBRCU'
结合IDA中的汇编 每一次都是执行到一个块(Block)的开头地址才调用检查函数 关于块 [官方文档][https://docs.angr.io/en/latest/core-concepts/toplevel.html]有解释 可以看到循环的部分也记录了循环的次数次 但是有分支的部分两个分支都有被记录而且被记录的次序紧挨着 这里猜测执行的模式是先扫描所有块 然后再在关键的块进行快照并爆破 以后再细究
为某段程序的符号执行设定初始值 angr_symbolic_registers | 寄存器的初始化 程序设置的读入函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 .text:0804890C ; int get_user_input() .text:0804890C public get_user_input .text:0804890C get_user_input proc near .text:0804890C .text:0804890C var_18= dword ptr -18h .text:0804890C var_14= dword ptr -14h .text:0804890C var_10= dword ptr -10h .text:0804890C var_C= dword ptr -0Ch .text:0804890C .text:0804890C ; __unwind { .text:0804890C 55 push ebp .text:0804890D 89 E5 mov ebp, esp .text:0804890F 83 EC 18 sub esp, 18h .text:08048912 65 8B 0D 14 00 00 00 mov ecx, large gs:14h .text:08048919 89 4D F4 mov [ebp+var_C], ecx .text:0804891C 31 C9 xor ecx, ecx .text:0804891E 8D 4D F0 lea ecx, [ebp+var_10] .text:08048921 51 push ecx .text:08048922 8D 4D EC lea ecx, [ebp+var_14] .text:08048925 51 push ecx .text:08048926 8D 4D E8 lea ecx, [ebp+var_18] .text:08048929 51 push ecx .text:0804892A 68 93 8A 04 08 push offset aXXX ; "%x %x %x" .text:0804892F E8 9C FA FF FF call ___isoc99_scanf .text:0804892F .text:08048934 83 C4 10 add esp, 10h .text:08048937 8B 4D E8 mov ecx, [ebp+var_18] .text:0804893A 89 C8 mov eax, ecx .text:0804893C 8B 4D EC mov ecx, [ebp+var_14] .text:0804893F 89 CB mov ebx, ecx .text:08048941 8B 4D F0 mov ecx, [ebp+var_10] .text:08048944 89 CA mov edx, ecx .text:08048946 90 nop .text:08048947 8B 4D F4 mov ecx, [ebp+var_C] .text:0804894A 65 33 0D 14 00 00 00 xor ecx, large gs:14h .text:08048951 74 05 jz short locret_8048958 .text:08048951 .text:08048953 E8 48 FA FF FF call ___stack_chk_fail .text:08048953 .text:08048958 locret_8048958: ; CODE XREF: get_user_input+45↑j .text:08048958 C9 leave .text:08048959 C3 retn
最后的结果等效于scanf("%x %x %x", eax, ebx, edx) 早期的angr无法一次输入多个数据(现在测试是可以直接按照前两题的做法出结果的) 那就需要我们直接跳过读入数据的过程对eax, ebx, edx赋值 那么这次的simstate就不能设置为entry_state()了 而应该将入口设置为读入数据后一行代码:
1 2 start_addr = 0x804897B simstate = proj.factory.blank_state(addr=start_addr)
然后初始化simstate 将eax, ebx, edx设定为待定值:
1 2 3 4 5 simstate.regs.eax = claripy.BVS('eax' , 32 ) simstate.regs.ebx = claripy.BVS('ebx' , 32 ) simstate.regs.edx = claripy.BVS('edx' , 32 )
完整脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import angr, sys, claripyeip_record = [] branch_record = [] def is_succ (state ): print (f'eax: {hex (state.solver.eval (state.regs.eax))[2 :]} ebx: {hex (state.solver.eval (state.regs.ebx))[2 :]} edx: {hex (state.solver.eval (state.regs.edx))[2 :]} ' ) return b'Good Job' in state.posix.dumps(1 ) def is_fail (state ): return b'Try again' in state.posix.dumps(1 ) def main (argv ): proj = angr.Project('03_angr_symbolic_registers' , load_options={'auto_load_libs' :False }) start_addr = 0x804897B simstate = proj.factory.blank_state(addr=start_addr) simstate.regs.eax = claripy.BVS('eax' , 32 ) simstate.regs.ebx = claripy.BVS('ebx' , 32 ) simstate.regs.edx = claripy.BVS('edx' , 32 ) simmgr = proj.factory.simgr(simstate) simmgr.explore(find=is_succ, avoid=is_fail) if simmgr.found: print (simmgr.found[0 ].posix.dumps(0 )) if __name__ == '__main__' : main(sys.argv)
angr_symbolic_stack | 栈的初始化 和上一题一样 这次的程序要求一次输入两个值 不同的是这次直接存放到栈上 不用寄存器做媒介:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 .text:08048679 ; int handle_user() .text:08048679 public handle_user .text:08048679 handle_user proc near ; CODE XREF: main+21↓p .text:08048679 .text:08048679 var_10= dword ptr -10h .text:08048679 var_C= dword ptr -0Ch .text:08048679 .text:08048679 ; __unwind { .text:08048679 55 push ebp .text:0804867A 89 E5 mov ebp, esp .text:0804867C 83 EC 18 sub esp, 18h .text:0804867F 83 EC 04 sub esp, 4 .text:08048682 8D 45 F0 lea eax, [ebp+var_10] .text:08048685 50 push eax .text:08048686 8D 45 F4 lea eax, [ebp+var_C] .text:08048689 50 push eax .text:0804868A 68 B3 87 04 08 push offset aUU ; "%u %u" .text:0804868F E8 DC FC FF FF call ___isoc99_scanf .text:0804868F .text:08048694 83 C4 10 add esp, 10h .text:08048697 8B 45 F4 mov eax, [ebp+var_C] .text:0804869A 83 EC 0C sub esp, 0Ch .text:0804869D 50 push eax .text:0804869E E8 06 FE FF FF call complex_function0 .text:0804869E .text:080486A3 83 C4 10 add esp, 10h .text:080486A6 89 45 F4 mov [ebp+var_C], eax .text:080486A9 8B 45 F0 mov eax, [ebp+var_10] .text:080486AC 83 EC 0C sub esp, 0Ch .text:080486AF 50 push eax .text:080486B0 E8 DC FE FF FF call complex_function1 .text:080486B0 .text:080486B5 83 C4 10 add esp, 10h .text:080486B8 89 45 F0 mov [ebp+var_10], eax .text:080486BB 8B 45 F4 mov eax, [ebp+var_C] .text:080486BE 3D D1 24 30 77 cmp eax, 773024D1h .text:080486C3 75 0A jnz short loc_80486CF .text:080486C3 .text:080486C5 8B 45 F0 mov eax, [ebp+var_10] .text:080486C8 3D CF 11 43 BC cmp eax, 0BC4311CFh .text:080486CD 74 12 jz short loc_80486E1 .text:080486CD .text:080486CF .text:080486CF loc_80486CF: ; CODE XREF: handle_user+4A↑j .text:080486CF 83 EC 0C sub esp, 0Ch .text:080486D2 68 B9 87 04 08 push offset s ; "Try again." .text:080486D7 E8 74 FC FF FF call _puts .text:080486D7 .text:080486DC 83 C4 10 add esp, 10h .text:080486DF EB 10 jmp short loc_80486F1 .text:080486DF .text:080486E1 ; --------------------------------------------------------------------------- .text:080486E1 .text:080486E1 loc_80486E1: ; CODE XREF: handle_user+54↑j .text:080486E1 83 EC 0C sub esp, 0Ch .text:080486E4 68 C4 87 04 08 push offset aGoodJob ; "Good Job." .text:080486E9 E8 62 FC FF FF call _puts .text:080486E9 .text:080486EE 83 C4 10 add esp, 10h .text:080486EE .text:080486F1 .text:080486F1 loc_80486F1: ; CODE XREF: handle_user+66↑j .text:080486F1 90 nop .text:080486F2 C9 leave .text:080486F3 C3 retn
输入函数等效于scanf("%u %u", [val0](ebp - 0xC), [val1](ebp - 0x10)) 为了在栈上正确的位置进行值的符号化 简单看一下栈输入完后栈的结构:
1 2 3 ebp - 4 ebp - 10h ...| ebx | ... | val0 | val1 | ... ebp - 0 ebp - 8h ebp - Ch
也就是说第一个值在ebp-8到ebp-10h之间 第二个在ebp-10h到ebp-C之间 为了模拟进入函数的过程 初始状态中将esp赋给ebp:
1 2 state = proj.factory.blank_state(addr = 0x8048697 ) state.regs.ebp = state.regs.esp
再对ebp-8处的栈空间进行符号化:
1 2 3 4 p1 = claripy.BVS('p1' , 32 ) p2 = claripy.BVS('p2' , 32 ) state.stack_push(p1) state.stack_push(p2)
完整脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import angr, sys, claripydef is_succ (state ): return b'Good Job' in state.posix.dumps(1 ) def is_fail (state ): return b'Try again' in state.posix.dumps(1 ) def main (argv ): proj = angr.Project('04_angr_symbolic_stack' , load_options={'auto_load_libs' : False }) state = proj.factory.blank_state(addr = 0x8048697 ) state.regs.ebp = state.regs.esp state.regs.esp -= 8 p1 = claripy.BVS('p1' , 32 ) p2 = claripy.BVS('p2' , 32 ) state.stack_push(p1) state.stack_push(p2) simgr = proj.factory.simulation_manager(state) simgr.explore(find=is_succ, avoid=is_fail) if simgr.found: print (f'p1: {hex (simgr.found[0 ].solver.eval (p1))} \np2: {hex (simgr.found[0 ].solver.eval (p2))} ' ) else : print ('Answer not found' ) if __name__ == '__main__' : main(sys.argv)
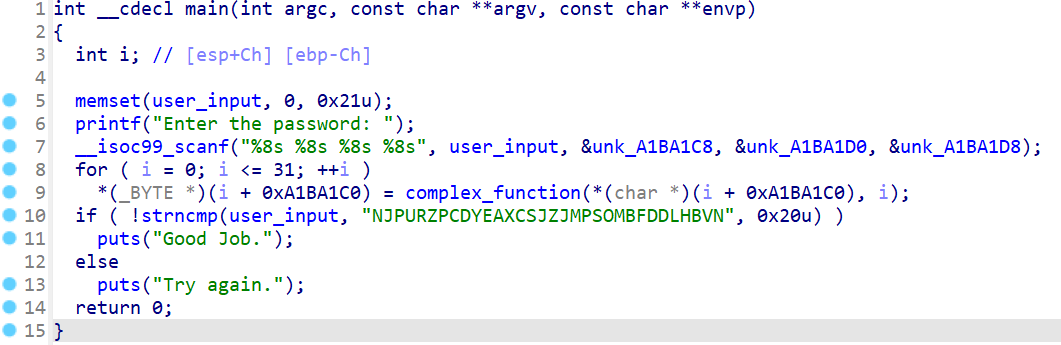
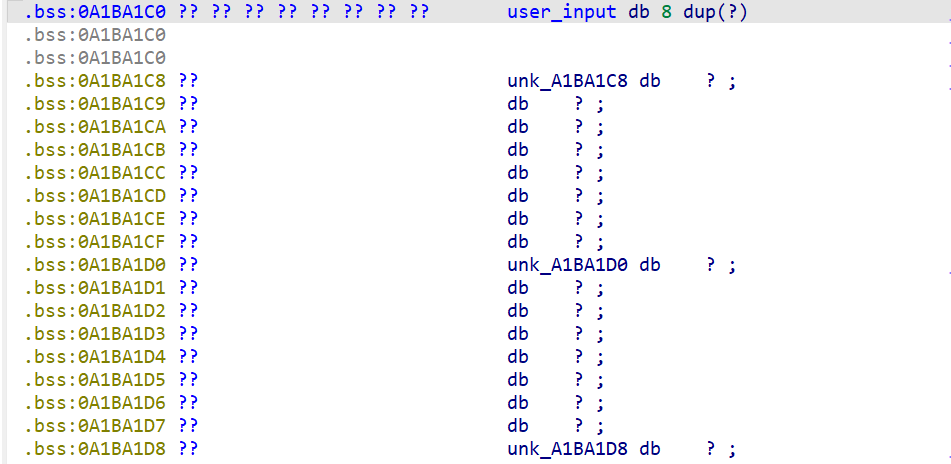
angr_symbolic_memory | 内存空间初始化1 如果程序要用到的值不是本地变量而是全局变量 那就需要对对应的内存区域进行符号化再求解 这题校验的值放在.bss段上:
和之前一样跳过输入部分(现版本angr已经支持直接输入 可以按照第1, 2题的方法做 下面一题也是) 并对目标区域进行符号化(其实栈的初始化本质上也是内存区域初始化 可以用一样的方法进行值的符号化) 完整脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import angr, sys, claripydef is_succ (state ): return b'Good Job' in state.posix.dumps(1 ) def is_fail (state ): return b'Try again' in state.posix.dumps(1 ) def main (argv ): proj = angr.Project('05_angr_symbolic_memory' , load_options={'auto_load_libs' : False }) state = proj.factory.blank_state(addr = 0x80485FE ) bss = 0xA1BA1C0 pws = [claripy.BVS('pw%d' % i, 64 ) for i in range (4 )] for i in range (4 ): state.memory.store(bss + i * 8 , pws[i]) simgr = proj.factory.simulation_manager(state) simgr.explore(find=is_succ, avoid=is_fail) if simgr.found: for i in range (4 ): print (simgr.found[0 ].solver.eval (pws[i], cast_to=bytes ), end = ' ' ) else : print ('Answer not found' ) if __name__ == '__main__' : main(sys.argv)
angr_symbolic_dynamic_memory | 内存空间初始化2 如果要符号化的内存区域一开始是不确定的 可以退而求其次不对原本要校验的区域进行符号化 而是更改要校验的区域将其固定下来 这题用malloc()进行内存分配:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 int __cdecl main (int argc, const char **argv, const char **envp) { char *v3; char *v4; int v6; int i; buffer0 = malloc (9u ); buffer1 = malloc (9u ); memset (buffer0, 0 , 9u ); memset (buffer1, 0 , 9u ); printf ("Enter the password: " ); __isoc99_scanf("%8s %8s" , buffer0, buffer1, v6); for ( i = 0 ; i <= 7 ; ++i ) { v3 = &buffer0[i]; *v3 = complex_function(buffer0[i], i); v4 = &buffer1[i]; *v4 = complex_function(buffer1[i], i + 32 ); } if ( !strncmp (buffer0, "UODXLZBI" , 8u ) && !strncmp (buffer1, "UAORRAYF" , 8u ) ) puts ("Good Job." ); else puts ("Try again." ); free (buffer0); free (buffer1); return 0 ; }
malloc分配的内存在.heap堆空间上 和本地变量一样一开始是不确定其地址的 那就直接改变buffer0[1]存放的内存地址:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import angr, sys, claripydef is_succ (state ): return b'Good Job' in state.posix.dumps(1 ) def is_fail (state ): return b'Try again' in state.posix.dumps(1 ) def main (argv ): proj = angr.Project('06_angr_symbolic_dynamic_memory' , load_options={'auto_load_libs' : False }) start = 0x08048696 state = proj.factory.blank_state(addr = start) p1 = 0xABCC8A4 p2 = 0xABCC8AC bss1 = 0xABCC890 bss2 = 0xABCC880 state.memory.store(p1, bss1, endness=proj.arch.memory_endness) state.memory.store(p2, bss2, endness=proj.arch.memory_endness) pws = [state.solver.BVS('p1' , 8 *8 ), state.solver.BVS('p2' , 8 *8 )] state.memory.store(bss1, pws[0 ]) state.memory.store(bss2, pws[1 ]) simgr = proj.factory.simulation_manager(state) simgr.explore(find=is_succ, avoid=is_fail) if simgr.found: print (simgr.found[0 ].solver.eval (pws[0 ], cast_to=bytes )) print (simgr.found[0 ].solver.eval (pws[1 ], cast_to=bytes )) else : print ('Answer not found' ) if __name__ == '__main__' : main(sys.argv)
angr_symbolic_file | 文件内容初始化 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 int __cdecl __noreturn main (int argc, const char **argv, const char **envp) { int i; memset (buffer, 0 , sizeof (buffer)); printf ("Enter the password: " ); __isoc99_scanf("%64s" , buffer); ignore_me(buffer, 0x40 u); memset (buffer, 0 , sizeof (buffer)); fp = fopen("OJKSQYDP.txt" , "rb" ); fread(buffer, 1u , 0x40 u, fp); fclose(fp); unlink("OJKSQYDP.txt" ); for ( i = 0 ; i <= 7 ; ++i ) *(_BYTE *)(i + 0x804A0A0 ) = complex_function(*(char *)(i + 0x804A0A0 ), i); if ( strncmp (buffer, "AQWLCTXB" , 9u ) ) { puts ("Try again." ); exit (1 ); } puts ("Good Job." ); exit (0 ); }
ignore_me()的作用就是将输入的内容放进文件里保存以防下面读不到文件 这题可以在读取文件内容后开始对buffer初始化(测试后发现甚至可以从头开始执行 angr也能求解出答案) 这里从读取文件开始学习一下文件内容的符号化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import angr, sys, claripydef is_succ (state ): return b'Good Job' in state.posix.dumps(1 ) def is_fail (state ): return b'Try again' in state.posix.dumps(1 ) def main (argv ): proj = angr.Project('07_angr_symbolic_file' , load_options={'auto_load_libs' : False }) start = 0x080488D6 file_name = 'OJKSQYDP.txt' file_size = 0x40 file_content = claripy.BVS('file_content' , file_size * 8 ) simgr_file = angr.storage.SimFile(file_name, content=file_content, size=file_size) state = proj.factory.blank_state(addr = start) state.fs.insert(file_name, simgr_file) simgr = proj.factory.simulation_manager(state) simgr.explore(find=is_succ, avoid=is_fail) if simgr.found: print (simgr.found[0 ].solver.eval (file_content, cast_to=bytes )) else : print ('Answer not found' ) if __name__ == '__main__' : main(sys.argv)
angr_constraints | 手动添加条件 当程序在循环进行多次判断 符号执行时会产生指数级的路径从而发生路径爆炸问题 比如这道题的判断逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 _BOOL4 __cdecl check_equals_AUPDNNPROEZRJWKB (char *input, unsigned int len) { int v3; unsigned int i; v3 = 0 ; for ( i = 0 ; i < len; ++i ) { if ( input[i] == *(i + 0x804A040 ) ) ++v3; } return v3 == len; } int __cdecl main (int argc, const char **argv, const char **envp) { int i; qmemcpy(&password, "AUPDNNPROEZRJWKB" , 16 ); memset (&buffer, 0 , 0x11 u); printf ("Enter the password: " ); __isoc99_scanf("%16s" , &buffer); for ( i = 0 ; i <= 15 ; ++i ) *(i + 134520912 ) = complex_function(*(i + 0x804A050 ), 15 - i); if ( check_equals_AUPDNNPROEZRJWKB(&buffer, 16 ) ) puts ("Good Job." ); else puts ("Try again." ); return 0 ; }
密文长度为16bytes 也就是循环中对比的次数是16次 加上最后判断是否正确的一次判断 可能的路径达到了2 ^ 17条 如果直接让angr用这个函数进行是否正确的判断肯定会运行很长时间 我们直接在判断前中断程序 让程序进入我们自己设置的限制条件的代码段:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import angr, sys, claripydef is_succ (state ): return b'Good Job' in state.posix.dumps(1 ) def is_fail (state ): return b'Try again' in state.posix.dumps(1 ) def main (argv ): proj = angr.Project('08_angr_constraints' , load_options={'auto_load_libs' : False }) start = 0x08048625 buf = 0x804A050 state = proj.factory.blank_state(addr = start) ans = state.solver.BVS('buf' , 8 *16 ) state.memory.store(buf, ans) simgr = proj.factory.simulation_manager(state) simgr.explore(find=0x08048673 ) if simgr.found: new_state = simgr.found[0 ] string_after_processed = new_state.memory.load(buf, 16 ) new_state.solver.add(string_after_processed == "AUPDNNPROEZRJWKB" ) print (new_state.solver.eval (ans, cast_to=bytes )) else : print ('Answer not found' ) if __name__ == '__main__' : main(sys.argv)
hook某个函数 angr_hooks | 通过调用地址hook函数 这一题尝试用另一种方式解决路径爆炸问题 像Frida hook一样将会产生路径爆炸的函数替换成自己写的函数
和上一题的对比逻辑差不多 都是一位一位比:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 _BOOL4 __cdecl check_equals_XYMKBKUHNIQYNQXE (int a1, unsigned int a2) { int v3; unsigned int i; v3 = 0 ; for ( i = 0 ; i < a2; ++i ) { if ( *(i + a1) == *(i + 0x804A044 ) ) ++v3; } return v3 == a2; } int __cdecl main (int argc, const char **argv, const char **envp) { _BOOL4 v3; int i; int j; qmemcpy(password, "XYMKBKUHNIQYNQXE" , 16 ); memset (buffer, 0 , 0x11 u); printf ("Enter the password: " ); __isoc99_scanf("%16s" , buffer); for ( i = 0 ; i <= 15 ; ++i ) *(i + 0x804A054 ) = complex_function(*(i + 0x804A054 ), 18 - i); equals = check_equals_XYMKBKUHNIQYNQXE(buffer, 16 ); for ( j = 0 ; j <= 15 ; ++j ) *(j + 0x804A044 ) = complex_function(*(j + 0x804A044 ), j + 9 ); __isoc99_scanf("%16s" , buffer); v3 = equals && !strncmp (buffer, password, 0x10 u); equals = v3; if ( v3 ) puts ("Good Job." ); else puts ("Try again." ); return 0 ; }
0x804A044和0x804A054分别就是password和buffer的地址 检查函数被调用的位置:
1 2 3 4 5 6 7 .text:080486A9 83 EC 08 sub esp, 8 .text:080486AC 6A 10 push 10h .text:080486AE 68 54 A0 04 08 push offset buffer .text:080486B3 E8 ED FE FF FF call check_equals_XYMKBKUHNIQYNQXE .text:080486B3 .text:080486B8 83 C4 10 add esp, 10h .text:080486BB A3 68 A0 04 08 mov ds:equals, eax
call语句长度是5bytes 要hook的位置不是函数的开头 是call的位置 同时还需要call指令的长度 hook脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import angr, sys, claripydef is_succ (state ): return b'Good Job' in state.posix.dumps(1 ) def is_fail (state ): return b'Try again' in state.posix.dumps(1 ) def main (argv ): proj = angr.Project('09_angr_hooks' , load_options={'auto_load_libs' : False }) state = proj.factory.entry_state() to_hook = 0x80486B3 lenth = 0x5 simgr = proj.factory.simulation_manager(state) @proj.hook(to_hook, length=lenth ) def hook_func (state ): to_cmp = state.memory.load(0x804A044 , 0x10 ) arg = state.memory.load(0x804A054 , 0x10 ) state.regs.eax = claripy.If(to_cmp == arg, claripy.BVV(1 , 32 ), claripy.BVV(0 , 32 )) simgr.explore(find=is_succ, avoid=is_fail) if simgr.found: print (simgr.found[0 ].posix.dumps(0 )) else : print ('Answer not found' ) if __name__ == '__main__' : main(sys.argv)
angr_simprocedures | 通过符号hook函数 当要hook的函数在多处被调用 并且hook的目的是彻底更改函数执行的内容就要对所有的调用地址进行hook 非常麻烦 例如这一题:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 int __cdecl main (int argc, const char **argv, const char **envp) { int i; char s[17 ]; unsigned int v6; v6 = __readgsdword(0x14 u); memcpy (&password, "ORSDDWXHZURJRBDH" , 0x10 u); memset (s, 0 , sizeof (s)); printf ("Enter the password: " ); __isoc99_scanf("%16s" , s); for ( i = 0 ; i <= 15 ; ++i ) s[i] = complex_function(s[i], 18 - i); if ( check_equals_ORSDDWXHZURJRBDH((int )s, 0x10 u) ) puts ("Good Job." ); else puts ("Try again." ); return 0 ; }
程序被虚拟控制流混淆(虽然IDA的反汇编可以轻松优化出唯一会执行的路径) 这样就需要对函数的符号进行hook:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import angr, sys, claripydef is_succ (state ): return b'Good Job' in state.posix.dumps(1 ) def is_fail (state ): return b'Try again' in state.posix.dumps(1 ) def main (argv ): proj = angr.Project('10_angr_simprocedures' , load_options={'auto_load_libs' : False }) start = 0x0 state = proj.factory.entry_state() class simpro (angr.SimProcedure): def run (self, user_input, lenth ): to_cmp = "ORSDDWXHZURJRBDH" content = self.state.memory.load(user_input, lenth) return claripy.If(content == to_cmp, claripy.BVV(1 , 32 ), claripy.BVV(0 , 32 )) proj.hook_symbol('check_equals_ORSDDWXHZURJRBDH' , simpro()) simgr = proj.factory.simulation_manager(state) simgr.explore(find=is_succ, avoid=is_fail) if simgr.found: print (simgr.found[0 ].posix.dumps(0 )) else : print ('Answer not found' ) if __name__ == '__main__' : main(sys.argv)
angr_sim_scanf | hook库函数 hook库函数的流程和上一题一样 这题也是虚拟控制流混淆 要用hook绕过angr只能输入一个参数的问题(现版本已经没有这个问题):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 int __cdecl main (int argc, const char **argv, const char **envp) { int i; char s[20 ]; unsigned int v7; v7 = __readgsdword(0x14 u); memset (s, 0 , sizeof (s)); qmemcpy(s, "SUQMKQFX" , 8 ); for ( i = 0 ; i <= 7 ; ++i ) s[i] = complex_function(s[i], i); printf ("Enter the password: " ); __isoc99_scanf("%u %u" , buffer0, buffer1); if ( !strncmp (buffer0, s, 4u ) && !strncmp (buffer1, &s[4 ], 4u ) ) puts ("Good Job." ); else puts ("Try again." ); return 0 ; }
虽然函数原型是可变参数 但是构造hook函数的时候根据要hook的那个scanf进行参数个数的设置就行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import angr, sys, claripydef is_succ (state ): return b'Good Job' in state.posix.dumps(1 ) def is_fail (state ): return b'Try again' in state.posix.dumps(1 ) def main (argv ): proj = angr.Project('11_angr_sim_scanf' , load_options={'auto_load_libs' : False }) start = 0x0 class sim_scanf (angr.SimProcedure): def run (self, format_string, buf1, buf2 ): p1, p2 = claripy.BVS('p1' , 8 *4 ), claripy.BVS('p2' , 8 *4 ) self.state.memory.store(buf1, p1, endness=proj.arch.memory_endness) self.state.memory.store(buf2, p2, endness=proj.arch.memory_endness) self.state.globals ['ans' ] = (p1, p2) proj.hook_symbol('__isoc99_scanf' , sim_scanf()) state = proj.factory.entry_state() simgr = proj.factory.simulation_manager(state) simgr.explore(find=is_succ, avoid=is_fail) if simgr.found: solved_state = simgr.found[0 ] p1, p2 = solved_state.globals ['ans' ] print (solved_state.solver.eval (p1, cast_to=bytes ) + solved_state.solver.eval (p2, cast_to=bytes )) else : print ('Answer not found' ) if __name__ == '__main__' : main(sys.argv)
angr_veritesting | 不知道有没有用的技术 这题的官方解现在(2024.7.30)已经跑不出结果出来了 据官方文档 这种方法是结合静态符号分析来减少符号路径的条数 但是就算开启了也没办法解决本题路径爆炸问题 所以用之前的做法做这题 把路径爆炸的部分替换成用户函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import angr, sys, claripydef is_succ (state ): return b'Good Job' in state.posix.dumps(1 ) def is_fail (state ): return b'Try again' in state.posix.dumps(1 ) def main (argv ): proj = angr.Project('12_angr_veritesting' , load_options={'auto_load_libs' : False }) start = 0x0 state = proj.factory.entry_state() simgr = proj.factory.simgr(state, veritesting = True ) simgr.explore(find = 0x8048635 ) if simgr.found: now_state = simgr.found[0 ] def complex_function (a1, a2 ): return (a1 - 65 + 2 * a2) % 26 + 65 for i in range (32 ): ans = now_state.memory.load(now_state.regs.ebp.args[0 ] - 0x2d + i, 1 ) now_state.add_constraints(ans == complex_function(75 , i + 93 )) print (now_state.solver.eval (ans, cast_to=bytes ).decode(), end='' ) else : print ('Answer not found' ) if __name__ == '__main__' : main(sys.argv)
angr_static_binary | 静态编译程序的符号执行 如果程序是静态编译出来的 angr就会把库函数当成用户函数 在符号执行的时候会进入库函数进行完全的符号执行 相当于步入调试 以前识别出库函数使用的是步过调试 这时候就需要hook这些静态编译进程序的库函数 替换成angr自带的库函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import angr, sys, claripydef is_succ (state ): return b'Good Job' in state.posix.dumps(1 ) def is_fail (state ): return b'Try again' in state.posix.dumps(1 ) def main (argv ): proj = angr.Project('13_angr_static_binary' , load_options={'auto_load_libs' : False }) start = 0x0 state = proj.factory.entry_state() simgr = proj.factory.simulation_manager(state) proj.hook(0x8048D10 , angr.SIM_PROCEDURES['glibc' ]['__libc_start_main' ]()) proj.hook(0x804ED40 , angr.SIM_PROCEDURES['libc' ]['printf' ]()) proj.hook(0x804ED80 , angr.SIM_PROCEDURES['glibc' ]['__isoc99_scanf' ]()) proj.hook(0x8048280 , angr.SIM_PROCEDURES['libc' ]['strcmp' ]()) proj.hook(0x804F350 , angr.SIM_PROCEDURES['libc' ]['puts' ]()) simgr.explore(find=is_succ, avoid=is_fail) if simgr.found: print (simgr.found[0 ].posix.dumps(0 )) else : print ('Answer not found' ) if __name__ == '__main__' : main(sys.argv)
hook的地址就用库函数的起始地址 区分是glibc还是libc的函数看前面有没有两个下划线就行
angr_shared_library | 符号执行动态链接库中的函数 angr的好处就是可以设定初始条件直接符号执行一段代码 而不用像调试器一样如果是库的话要附加到程序上才能调试 这题要符号执行一个外部库的函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 int __cdecl main (int argc, const char **argv, const char **envp) { char s[16 ]; unsigned int v5; v5 = __readgsdword(0x14 u); memset (s, 0 , sizeof (s)); printf ("Enter the password: " ); __isoc99_scanf("%8s" , s); if ( validate((int )s, 8 ) ) puts ("Good Job." ); else puts ("Try again." ); return 0 ; } _BOOL4 __cdecl validate (char *s1, int a2) { char *v3; char s2[20 ]; int j; int i; if ( a2 <= 7 ) return 0 ; for ( i = 0 ; i <= 19 ; ++i ) s2[i] = 0 ; qmemcpy(s2, "PVBLVTFT" , 8 ); for ( j = 0 ; j <= 7 ; ++j ) { v3 = &s1[j]; *v3 = complex_function(s1[j], j); } return strcmp (s1, s2) == 0 ; }
加载库需要指定基址 这里选base = 0x4000000:
1 2 3 4 5 6 7 8 base = 0x4000000 func_offset = 0x6D7 proj = angr.Project('lib14_angr_shared_library.so' , load_options={ 'main_opts' : { 'custom_base_addr' : base } })
为了设定函数执行的初始值需要一个call_state来指定函数起始地址和参数 这里假定用户输入的字符串存放地址是0x3000000:
state = proj.factory.call_state(base + func_offset, 0x3000000, 8)
后面的流程就和符号执行普通的程序一样了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import angr, sys, claripydef main (argv ): base = 0x4000000 func_offset = 0x6D7 proj = angr.Project('lib14_angr_shared_library.so' , load_options={ 'main_opts' : { 'custom_base_addr' : base } }) state = proj.factory.call_state(base + func_offset, 0x3000000 , 8 ) pw = claripy.BVS('pw' , 8 * 8 ) state.memory.store(0x3000000 , pw) simgr = proj.factory.simulation_manager(state) simgr.explore(find = base + 0x783 ) if simgr.found: new_state = simgr.found[0 ] new_state.add_constraints(new_state.regs.eax == 1 ) print (new_state.solver.eval (pw, cast_to=bytes )) else : print ('Answer not found' ) if __name__ == '__main__' : main(sys.argv)
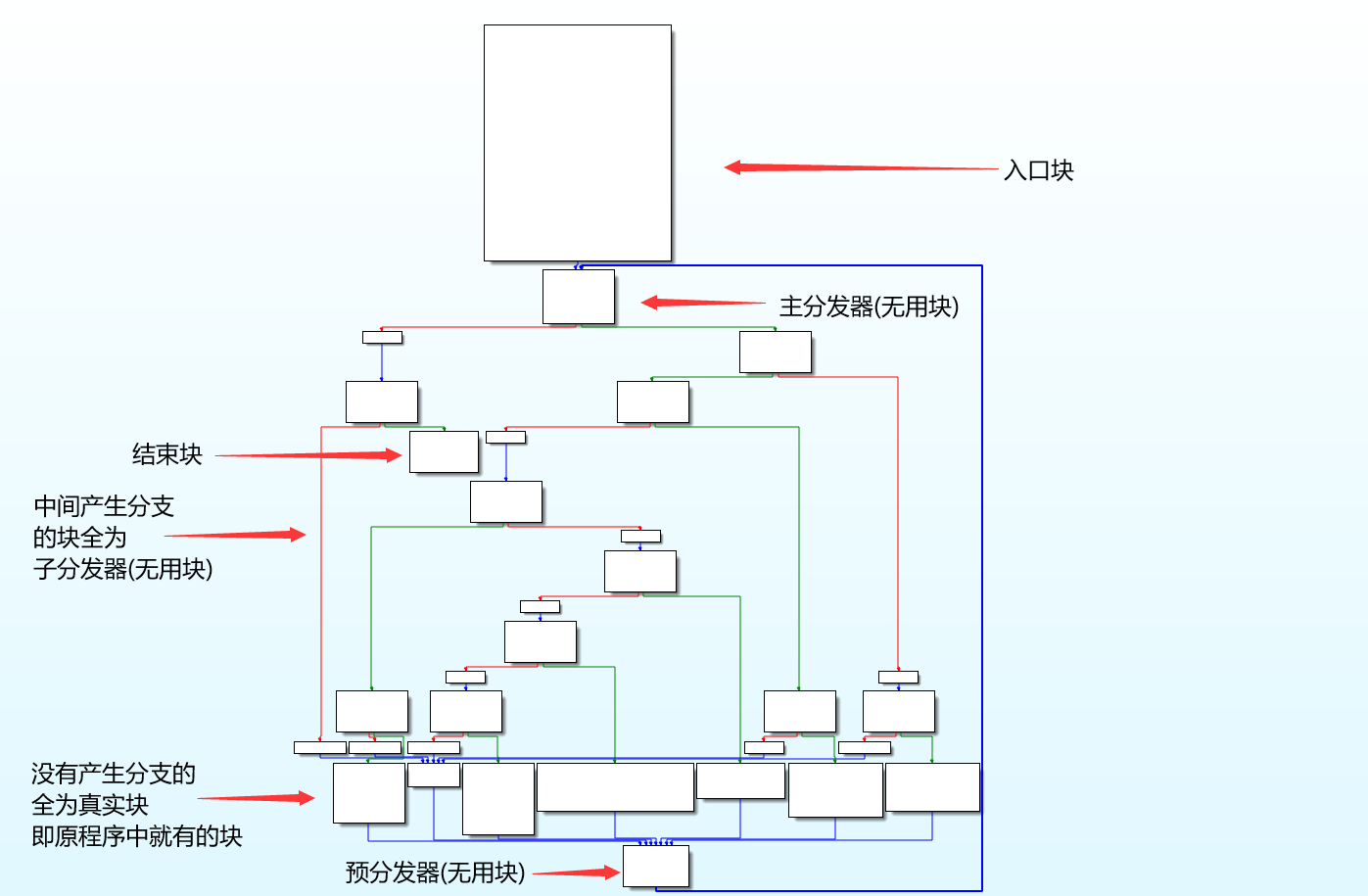
用Angr实现去控制流平坦化 开工之前先简单了解一下控制流平坦化的原理 去平坦化的核心任务就是恢复各个真实块(relevant block) 即原程序中就有的块之间的联系 而用Angr完成这项任务的难点有:
angr自带的块对象与IDA中graph view的block有区别 angr产生的控制流图(ControlFlow Graph, CFG)会被call指令分割 而IDA中的块直到跳转才会结束一个块 幸运的是官方的附带组件库angr_management中有一个转化angr CFG为IDA CFG的函数 但是同时也带来了第二个问题
angr_management中的to_supergraph产生的IDA CFG实际上是networkx库中的DI-Graph(有向图)类的派生类 相比angr CFG 可操作性直线下降
对原来产生分支的块的处理
这里一步步地进行去平坦化并在遇到这些问题时进行解释
获取各种块以方便后续的操作 这里就要发挥IDA CFG的优势了 根据上文引用的资料 各个块之间的界限以及各自的特征(以有向图的视角看 特征就是一个块的in-degree和out-degree)还是非常明显的:
将angr CFG变成IDA CFG后根据特征汇总每种块:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 def Get_CFG (proj : angr.Project ): cfg = None try : cfg = proj.analyses.CFGFast(normalize=True , force_complete_scan=False ) except : cfg = proj.analyses.CFGFast(normalize=True ) addr = int (args.addr, 16 ) if args.addr != 'main' else args.addr cfg = cfg.functions[addr].transition_graph IDA_cfg = graph.to_supergraph(cfg) return IDA_cfg def Get_Blocks (cfg ) -> dict : blocks = {} for node in cfg.nodes(): if cfg.in_degree(node) == 0 : blocks['entry' ] = node elif cfg.out_degree(node) == 0 : blocks['exit' ] = node blocks['main_dispatcher' ] = list (cfg.successors(blocks['entry' ]))[0 ] for node in cfg.predecessors(blocks['main_dispatcher' ]): if cfg.in_degree(node) != 0 : blocks['pre_dispatcher' ] = node break blocks['relevant' ] = [blocks['entry' ]] + [node for node in cfg.predecessors(blocks['pre_dispatcher' ]) if cfg.in_degree(node) == 1 ] + [blocks['exit' ]] blocks['irrelevant' ] = [node for node in cfg.nodes() if node not in blocks['relevant' ] and node != blocks['main_dispatcher' ] and node != blocks['pre_dispatcher' ]] return blocks
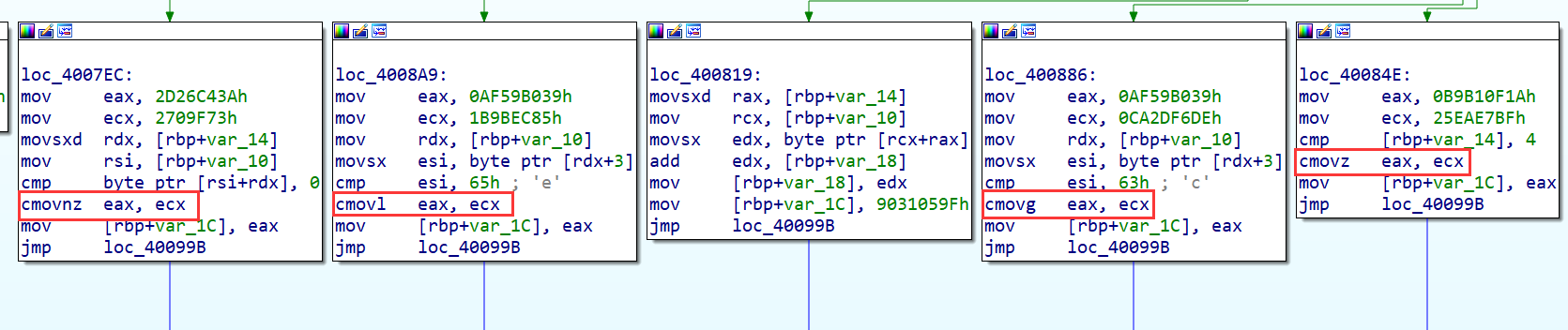
获取真实块的详细信息 这一步的目的是为下一步重建真实块之间的联系做铺垫 真实块在原程序中最多有两个out-degree 也就是说这里要对真实块进行分类 最简单的就是没有in-degree和没有out-degree的入口和终止块 剩下的程序内容可以分为有分支和无分支的真实块 稍微了解一下(x86_64)控制流平坦化的实现就能发现 原本的jx跳转都需要转化为对对整个控制流起决定性的关键值的分支化赋值 具体实现就是采用cmovxx指令:
cmovxx指令会根据zf, sf等标志位来对源寄存器进行赋值 例如cmovz会在zf=1时执行mov eax, ecx反之什么也不干 在确定框架的前提下用angr CFG自带的.capstone.ins方法来获取汇编指令 并用汇编指令来判断该块是否会产生分支 这里就会体现第1, 2点的缺陷了 因为用IDA CFG创建的真实块如果调用某函数的话 在对应的angr CFG中会是分隔的一个或几个块 这里用递归的方法找到angr CFG中包含jmp指令的块来保证已经分析完一个完整IDA CFG块
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def Get_branch (block_addr, all_branches, target, _from =None , flag=False ) -> bool : if _from is None : _from = block_addr all_branches[_from ] = [None , None ] block = proj.factory.block(block_addr) def NOP (state ): pass block_ins = block.capstone.insns for ins in block_ins: if ins.mnemonic == 'call' : proj.hook(ins.address, hook=NOP, length=ins.size) elif ins.mnemonic.startswith('cmov' ): all_branches[_from ][0 ], all_branches[_from ][1 ] = ins.address, ins.mnemonic flag = True if ins.mnemonic == 'jmp' or ins.mnemonic == 'retn' : all_branches[_from ].append(ins.address) return flag else : return Get_branch(ins.address + ins.size, all_branches, target, _from , flag)
最后all_branches就会包含所有真实块的3个信息:起始地址, 分支类型(若没有则为None), 结束地址 在后面的恢复控制流中会用到
重建控制流 接下来只需要根据分支类型来确定真实块间的关系就算是基本完成任务了 但是难点也来了 原本我的想法是不采用以真实块作为起点的宽搜方式 而是从入口块开始执行 期待angr的符号执行会在cmovxx指令自动分离出两个active 然后只要不断使用step()方法直到active.addr出现在真实块的起始地址里就能轻松获取控制流 但是angr只会在跳转产生分支 根本不鸟我 完全没有产生分支 似了
然后我的想法是根据分支类型来设置sf, zf等标志位 手动产生两条active 但是angr本来设计来就是遍历所有可能的跳转的 根本没有标志位 又似了
最后在网上找到了一种方法 通过控制angr底层的vex IR的执行来达到上面第二种尝试的目的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 def Get_successors (node, targets : list , branch_sign=None , cond=None ): if branch_sign is None : state = proj.factory.blank_state(addr=node.addr, remove_options={angr.sim_options.LAZY_SOLVES}) simgr = proj.factory.simulation_manager(state) while True : simgr.step() if simgr.active[0 ].addr in targets: break return simgr.active[0 ].addr else : def apply_branch (state ): expressions = list (state.scratch.irsb.statements[state.inspect.statement].expressions) if expressions and isinstance (expressions[0 ], pyvex.expr.ITE): state.scratch.temps[expressions[0 ].cond.tmp] = cond state.inspect._breakpoints['statement' ] = [] state = proj.factory.blank_state(addr=node.addr, remove_options={angr.sim_options.LAZY_SOLVES}) state.inspect.b('statement' , when=angr.BP_BEFORE, action=apply_branch) simgr = proj.factory.simulation_manager(state) while True : simgr.step() if simgr.active[0 ].addr in targets: break return simgr.active[0 ].addr new_cfg = nx.DiGraph() new_cfg.add_node(blocks['relevant' ][0 ]) relevant_addrs = [node.addr for node in blocks['relevant' ][1 :]] all_branches = {} end = Get_successors(blocks['relevant' ][0 ], relevant_addrs) end = blocks['relevant' ][relevant_addrs.index(end) + 1 ] new_cfg.add_edge(blocks['relevant' ][0 ], end) while True : nodes = [node for node in new_cfg.nodes() if new_cfg.out_degree(node) == 0 and node != blocks['exit' ]] if not nodes: break for node in nodes: Get_branch(node.addr, all_branches, blocks['pre_dispatcher' ].addr) if all_branches[node.addr][0 ] is None : end = Get_successors(node, relevant_addrs) end = blocks['relevant' ][relevant_addrs.index(end) + 1 ] new_cfg.add_edge(node, end) continue else : end_true = Get_successors(node, relevant_addrs, all_branches[node.addr][0 ], claripy.BVV(1 , 1 )) end_false = Get_successors(node, relevant_addrs, all_branches[node.addr][0 ], claripy.BVV(0 , 1 )) end_true, end_false = blocks['relevant' ][relevant_addrs.index(end_true) + 1 ], blocks['relevant' ][relevant_addrs.index(end_false) + 1 ] new_cfg.add_edges_from([(node, end_true), (node, end_false)])
简单来说就是cmovxx的指令转化为vexcode时必定会产生v3 = ITE(cond, v1, v2)指令 通过更改cond就能达到上面的尝试的目的 同时分析的过程中打印出vex IR也能注意到 当原本的指令为cmovx v1, v2时 对应的vex IR总为v1 = ITE(cond, v1, v2) 相反 如果原来指令是cmovnx 那么vex IR就会是v1 = ITE(cond, v2, v1) 也就是说当设置cond为1时 执行的就是符号位满足执行mov指令的条件 那么当cond为1时cmovxx就完美对应了jxx
patch程序 上面已经完成了所有困难的任务了 接下来要做的就是根据重建的控制流图来patch程序 这里将所有的无用块都patch成nop以方便后续对某些无用块的利用 同时对有分支的真实块在cmovxx处开始patch 那么剩余的真实块也需要patch成nop以防指令识别错误:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 with open (args.path, 'rb' ) as f: origin = bytearray (f.read()) base = proj.loader.main_object.min_addr arch = proj.arch.name if arch == 'AMD64' : ks = ks.Ks(ks.KS_ARCH_X86, ks.KS_MODE_64) for node in blocks['irrelevant' ] + [blocks['pre_dispatcher' ]] + [blocks['main_dispatcher' ]]: origin[node.addr - base:node.addr - base + node.size] = ks.asm('nop' )[0 ] * node.size node = blocks['main_dispatcher' ] first_relevant = list (new_cfg.successors([node for node in new_cfg.nodes() if new_cfg.in_degree(node) == 0 ][0 ]))[0 ] new_opcode = ks.asm(f'jmp {hex (first_relevant.addr)} ' , node.addr)[0 ] origin[node.addr - base:node.addr - base + len (new_opcode)] = new_opcode nodes = [node for node in new_cfg if new_cfg.in_degree(node) and new_cfg.out_degree(node)] for node in nodes: follows = list (new_cfg.successors(node)) if len (follows) == 1 : patch_addr = all_branches[node.addr][2 ] new_opcode = ks.asm(f'jmp {hex (follows[0 ].addr)} ' , patch_addr)[0 ] origin[patch_addr - base:patch_addr - base + len (new_opcode)] = new_opcode else : patch_addr = all_branches[node.addr][0 ] end_addr = all_branches[node.addr][2 ] origin[patch_addr - base:end_addr - base] = ks.asm('nop' )[0 ] * (end_addr - patch_addr) f1, f2 = follows[0 ], follows[1 ] op1 = x86_64_book[all_branches[node.addr][1 ]] + ' ' + hex (f1.addr) new_opcode1 = ks.asm(op1, patch_addr)[0 ] op2 = 'jmp ' + hex (f2.addr) new_opcode2 = ks.asm(op2, patch_addr + len (new_opcode1))[0 ] origin[patch_addr - base:patch_addr - base + len (new_opcode1 + new_opcode2)] = new_opcode1 + new_opcode2 with open (args.output, 'wb' ) as f_: f_.write(bytes (origin))
这里还要提出 将真实块添加到new_cfg中时是以 先加入cond = 1到达的下一个真实块后加入cond = 0到达的下一个真实块的顺序加入的 这个脚本能成功运行基于networkx对加入顺序的记忆性 当用.successors()方法取出时会按同样的顺序取出
完整代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 import angr, logging, pyvex, claripy, binascii, argparseimport networkx as nximport keystone as ksfrom angrmanagement.utils import graphparser = argparse.ArgumentParser(description='Deflat the program' ) parser.add_argument('-i' , '--path' , help ='The path to input program' , required=True ) parser.add_argument('-a' , '--addr' , help ='The address of the function you want to deflat, if not given, deflat main' , required=False , default='main' , type =str ) parser.add_argument('-o' , '--output' , help ='The name of output program' , required=True ) parser.add_argument('-g' , '--graph' , help ='Draw the graph of the CFG after deflated, off as default' , required=False , action='store_true' ) parser.add_argument('-v' , '--vex' , help ='Print the vex code of the relevant block, off as default' , required=False , action='store_true' ) args = parser.parse_args() logging.getLogger('angr' ).setLevel('ERROR' ) proj = angr.Project(args.path, load_options={'auto_load_libs' : False }) x86_64_book = {'cmovz' : 'jz' , 'cmove' : 'jz' , 'cmovnz' : 'jnz' , 'cmovne' : 'jnz' , 'cmovg' : 'jg' , 'cmovl' : 'jl' , 'cmovge' : 'jge' , 'cmovle' : 'jle' , 'jmp' : 'jmp' , 'call' : 'call' , 'nop' : 'nop' , 'ret' : [['ret' , 'retn' ], '' ], 'name' : 'x86_64' } arm_book = {'moveq' : 'beq' , 'movne' : 'bne' , 'movgt' : 'bgt' , 'movlt' : 'blt' , 'movge' : 'bge' , 'movle' : 'ble' , 'jmp' : 'b' , 'call' : 'bl' , 'nop' : 'nop' , 'ret' : [['bx' ], 'lr' ], 'name' : 'arm' } Ins_book = {'AMD64' : x86_64_book, 'ARMEL' : arm_book, 'X86' : x86_64_book} KSS = {'AMD64' : ks.Ks(ks.KS_ARCH_X86, ks.KS_MODE_64), 'ARMEL' : ks.Ks(ks.KS_ARCH_ARM, ks.KS_MODE_ARM), 'X86' : ks.Ks(ks.KS_ARCH_X86, ks.KS_MODE_32)} book = Ins_book[proj.arch.name] ks = KSS[proj.arch.name] def Get_CFG (proj : angr.Project ): cfg = None try : cfg = proj.analyses.CFGFast(normalize=True , force_complete_scan=False ) except : cfg = proj.analyses.CFGFast(normalize=True ) addr = int (args.addr, 16 ) if args.addr != 'main' else args.addr cfg = cfg.functions[addr].transition_graph IDA_cfg = graph.to_supergraph(cfg) return IDA_cfg def Get_Blocks (cfg ) -> dict : blocks = {} for node in cfg.nodes(): if cfg.in_degree(node) == 0 : blocks['entry' ] = node elif cfg.out_degree(node) == 0 : blocks['exit' ] = node blocks['main_dispatcher' ] = list (cfg.successors(blocks['entry' ]))[0 ] for node in cfg.predecessors(blocks['main_dispatcher' ]): if cfg.in_degree(node) != 0 : blocks['pre_dispatcher' ] = node break blocks['relevant' ] = [blocks['entry' ]] + [node for node in cfg.predecessors(blocks['pre_dispatcher' ]) if cfg.in_degree(node) == 1 ] + [blocks['exit' ]] blocks['irrelevant' ] = [node for node in cfg.nodes() if node not in blocks['relevant' ] and node != blocks['main_dispatcher' ] and node != blocks['pre_dispatcher' ]] return blocks def Get_branch (block_addr, all_branches, target, _from =None , flag=False ) -> bool : if _from is None : _from = block_addr all_branches[_from ] = [None , None ] block = proj.factory.block(block_addr) def NOP (state ): pass block_ins = block.capstone.insns for ins in block_ins: if ins.mnemonic == book['call' ]: proj.hook(ins.address, hook=NOP, length=ins.size) print (f'hooked {hex (ins.address)} ' ) elif ins.mnemonic.startswith('cmov' ) or (ins.mnemonic.startswith('mov' ) and len (ins.mnemonic) > 3 and book['name' ] == 'arm' ): all_branches[_from ][0 ], all_branches[_from ][1 ] = ins.address, ins.mnemonic flag = True if ins.mnemonic == book['jmp' ] or (ins.mnemonic in book['ret' ][0 ] and ins.op_str == book['ret' ][1 ]): all_branches[_from ].append(ins.address) return flag else : return Get_branch(ins.address + ins.size, all_branches, target, _from , flag) def Get_successors (node, targets : list , branch_sign=None , cond=None ): if branch_sign is None : state = proj.factory.blank_state(addr=node.addr, remove_options={angr.sim_options.LAZY_SOLVES}) simgr = proj.factory.simulation_manager(state) while True : simgr.step() if simgr.active[0 ].addr in targets: break return simgr.active[0 ].addr else : def apply_branch (state ): expressions = list (state.scratch.irsb.statements[state.inspect.statement].expressions) if expressions and isinstance (expressions[0 ], pyvex.expr.ITE): if args.vex: block = proj.factory.block(node.addr) print (block.vex.pp()) state.scratch.temps[expressions[0 ].cond.tmp] = cond state.inspect._breakpoints['statement' ] = [] state = proj.factory.blank_state(addr=node.addr, remove_options={angr.sim_options.LAZY_SOLVES}) state.inspect.b('statement' , when=angr.BP_BEFORE, action=apply_branch) simgr = proj.factory.simulation_manager(state) while True : simgr.step() if simgr.active[0 ].addr in targets: break return simgr.active[0 ].addr if __name__ == '__main__' : cfg = Get_CFG(proj) blocks = Get_Blocks(cfg) new_cfg = nx.DiGraph() new_cfg.add_node(blocks['relevant' ][0 ]) relevant_addrs = [node.addr for node in blocks['relevant' ][1 :]] all_branches = {} print (f'Entry: {hex (blocks["entry" ].addr)} \nExit: {hex (blocks["exit" ].addr)} \nMain Dispatcher: {hex (blocks["main_dispatcher" ].addr)} \nPre Dispatcher: {hex (blocks["pre_dispatcher" ].addr)} \nRelevant: {[hex (node.addr) for node in blocks["relevant" ]]} \nIrrelevant: {[hex (node.addr) for node in blocks["irrelevant" ]]} ' ) input ('...' ) end = Get_successors(blocks['relevant' ][0 ], relevant_addrs) end = blocks['relevant' ][relevant_addrs.index(end) + 1 ] new_cfg.add_edge(blocks['relevant' ][0 ], end) while True : nodes = [node for node in new_cfg.nodes() if new_cfg.out_degree(node) == 0 and node != blocks['exit' ]] if not nodes: break for node in nodes: Get_branch(node.addr, all_branches, blocks['pre_dispatcher' ].addr) for branch in all_branches: print (f'{hex (branch)} : {all_branches[branch]} ' ) if all_branches[node.addr][0 ] is None : end = Get_successors(node, relevant_addrs) end = blocks['relevant' ][relevant_addrs.index(end) + 1 ] new_cfg.add_edge(node, end) continue else : end_true = Get_successors(node, relevant_addrs, all_branches[node.addr][0 ], claripy.BVV(1 , 1 )) end_false = Get_successors(node, relevant_addrs, all_branches[node.addr][0 ], claripy.BVV(0 , 1 )) end_true, end_false = blocks['relevant' ][relevant_addrs.index(end_true) + 1 ], blocks['relevant' ][relevant_addrs.index(end_false) + 1 ] new_cfg.add_edges_from([(node, end_true), (node, end_false)]) if args.graph: from matplotlib import pyplot as plt nx.draw(new_cfg, with_labels=True ) plt.show() with open (args.path, 'rb' ) as f: origin = bytearray (f.read()) base = proj.loader.main_object.mapped_base for node in blocks['irrelevant' ] + [blocks['pre_dispatcher' ]] + [blocks['main_dispatcher' ]]: origin[node.addr - base:node.addr - base + node.size] = ks.asm('nop' )[0 ] * (node.size // len (ks.asm('nop' )[0 ])) node = blocks['main_dispatcher' ] first_relevant = list (new_cfg.successors([node for node in new_cfg.nodes() if new_cfg.in_degree(node) == 0 ][0 ]))[0 ] new_opcode = ks.asm(book['jmp' ] + ' ' + hex (first_relevant.addr), node.addr)[0 ] origin[node.addr - base:node.addr - base + len (new_opcode)] = new_opcode nodes = [node for node in new_cfg if new_cfg.in_degree(node) and new_cfg.out_degree(node)] for node in nodes: follows = list (new_cfg.successors(node)) print (f'{hex (node.addr)} --> {[hex (follow.addr) for follow in follows]} ' ) if len (follows) == 1 : patch_addr = all_branches[node.addr][2 ] new_opcode = ks.asm(book['jmp' ] + ' ' + hex (follows[0 ].addr), patch_addr)[0 ] origin[patch_addr - base:patch_addr - base + len (new_opcode)] = new_opcode else : patch_addr = all_branches[node.addr][0 ] end_addr = all_branches[node.addr][2 ] origin[patch_addr - base:end_addr - base] = ks.asm('nop' )[0 ] * ((end_addr - patch_addr) // len (ks.asm('nop' )[0 ])) f1, f2 = follows[0 ], follows[1 ] op1 = book[all_branches[node.addr][1 ]] + ' ' + hex (f1.addr) new_opcode1 = ks.asm(op1, patch_addr)[0 ] op2 = book['jmp' ] + ' ' + hex (f2.addr) new_opcode2 = ks.asm(op2, patch_addr + len (new_opcode1))[0 ] origin[patch_addr - base:patch_addr - base + len (new_opcode1 + new_opcode2)] = new_opcode1 + new_opcode2 with open (args.output, 'wb' ) as f_: f_.write(bytes (origin))
总结&后续打算 学到虚脱
把其他框架的也加进来增强兼容性(24/8/20 已实现) 后面应该还会再用angr实现一下普通花指令的梭哈和绕过虚拟控制流
参考
https://security.tencent.com/index.php/blog/msg/112 https://34r7hm4n.me/0x401RevTrain-Tools/angr/10_%E5%88%A9%E7%94%A8angr%E7%AC%A6%E5%8F%B7%E6%89%A7%E8%A1%8C%E5%8E%BB%E9%99%A4%E6%8E%A7%E5%88%B6%E6%B5%81%E5%B9%B3%E5%9D%A6%E5%8C%96/ https://izayoishiki.github.io (请视奸他)
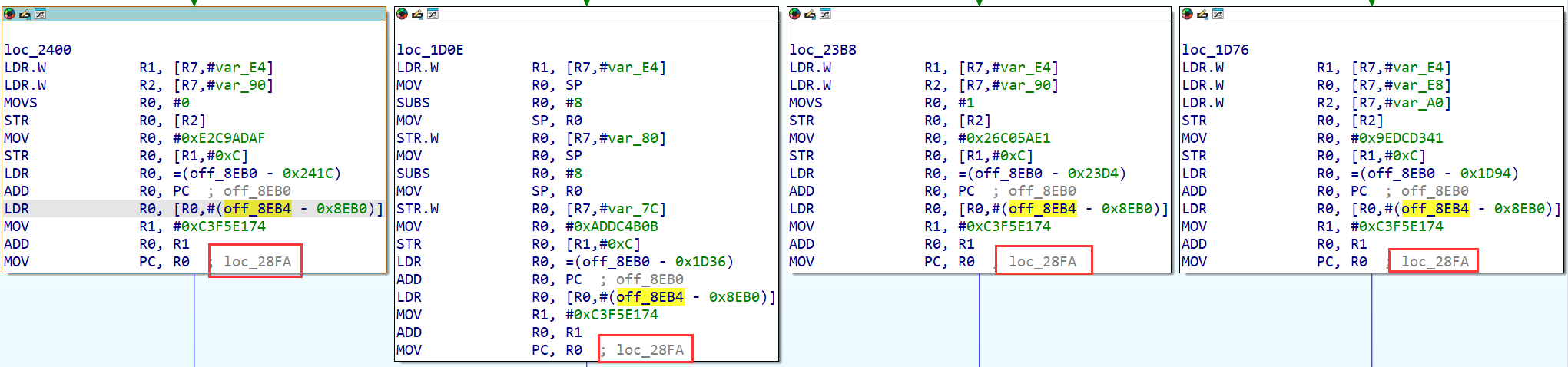
用Angr实现去虚拟跳转 / 控制流 实际上虚拟跳转比虚拟控制流要容易去除 因为IDA在硬编码中间数的前提下IDA可以直接计算出最终跳转的结果 例如:
但是使用Angr来去除虚拟跳转 / 控制流可以不用考虑那么多 只需要当作弱化的控制流平坦化处理就行 直接找到虚拟跳转的特征结构:
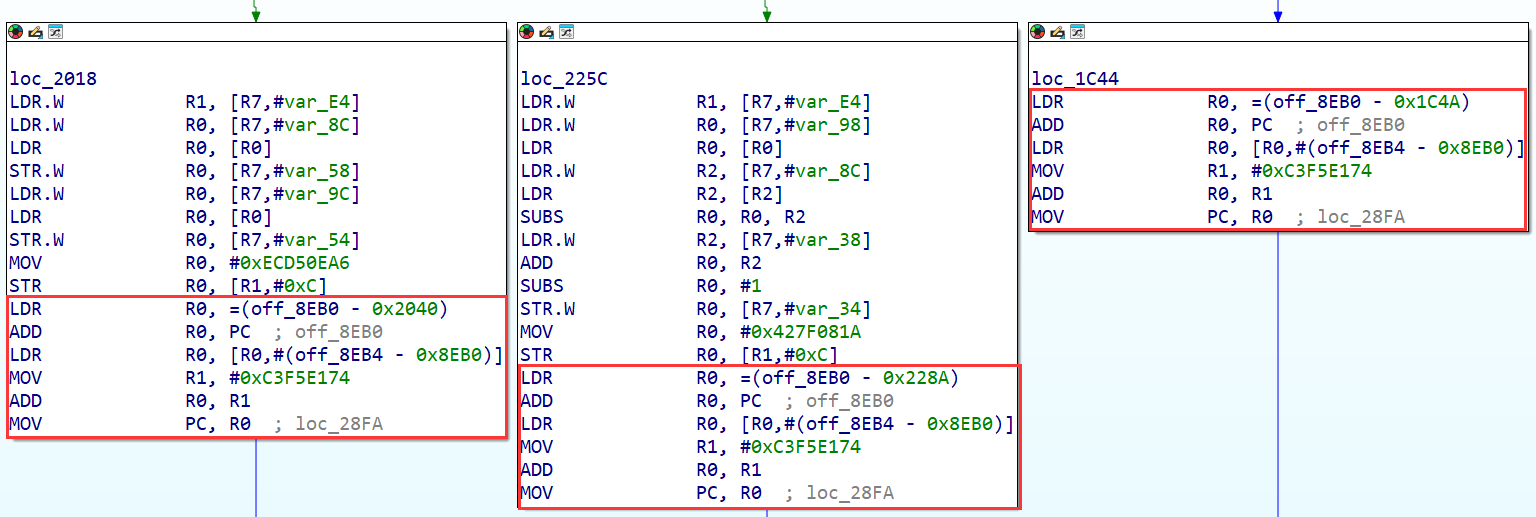
据此确定要开始符号执行的位置 虚拟跳转目标的计算和原程序控制流是完全没有关系的 可以直接从特征结构的头开始符号执行:
1 2 3 4 5 6 7 8 9 10 11 proj = angr.Project('fix2.so' , load_options={'auto_load_libs' : False }) ks = KSS[proj.arch.name] bias = -0x10 func_block = proj.factory.block(addr=start, size=end-start+1 ) to_patch = [] for ins in func_block.capstone.insns: if ins.insn.mnemonic == 'bl' : proj.hook(int (ins.op_str[3 :], 16 ), angr.SIM_PROCEDURES["stubs" ]["ReturnUnconstrained" ](), replace=True ) elif ins.insn.op_str.startswith('pc' ): to_patch.append(ins.address)
然后进行记录跳转后的地址进行patch即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 patch_addr = {} for addr in to_patch: state = proj.factory.blank_state(addr = addr + bias, remove_options={angr.options.LAZY_SOLVES}) simgr = proj.factory.simulation_manager(state) while simgr.active[0 ].addr != addr: simgr.step(num_inst=1 ) simgr.step(num_inst=1 ) to_jmp = simgr.active[0 ].addr patch_addr[addr] = to_jmp with open ('fix.so' , 'rb' ) as f: data = bytearray (f.read()) base = 0x400001 NOP = ks.asm('nop' )[0 ] for addr, jmp in patch_addr.items(): data[addr - base + bias:addr - base] = NOP * (abs (bias) // 2 ) print (f'Fill {hex (addr - base + bias)} to {hex (addr - base)} with NOP({abs (bias) // 2 } )' ) opcode = ks.asm(f'b {hex (jmp)} ' , addr + bias)[0 ] data[addr - base + bias:addr - base + bias + len (opcode)] = opcode print (f'Patched {hex (addr)} -> {hex (jmp)} ' ) fix_so = open ('fix.so' , 'wb' ) fix_so.write(data) fix_so.close()
完整代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 import angr, loggingimport keystone as ksimport capstone as cslogging.getLogger('angr' ).setLevel('ERROR' ) start, end = 0x401700 , 0x40290C KSS = {'AMD64' : ks.Ks(ks.KS_ARCH_X86, ks.KS_MODE_64), 'ARMEL' : ks.Ks(ks.KS_ARCH_ARM, ks.KS_MODE_THUMB), 'X86' : ks.Ks(ks.KS_ARCH_X86, ks.KS_MODE_32)} proj = angr.Project('fix2.so' , load_options={'auto_load_libs' : False }) ks = KSS[proj.arch.name] bias = -0x10 func_block = proj.factory.block(addr=start, size=end-start+1 ) to_patch = [] for ins in func_block.capstone.insns: if ins.insn.mnemonic == 'bl' : proj.hook(int (ins.op_str[3 :], 16 ), angr.SIM_PROCEDURES["stubs" ]["ReturnUnconstrained" ](), replace=True ) elif ins.insn.op_str.startswith('pc' ): to_patch.append(ins.address) patch_addr = {} for addr in to_patch: state = proj.factory.blank_state(addr = addr + bias, remove_options={angr.options.LAZY_SOLVES}) simgr = proj.factory.simulation_manager(state) while simgr.active[0 ].addr != addr: simgr.step(num_inst=1 ) simgr.step(num_inst=1 ) to_jmp = simgr.active[0 ].addr patch_addr[addr] = to_jmp with open ('fix.so' , 'rb' ) as f: data = bytearray (f.read()) base = 0x400001 NOP = ks.asm('nop' )[0 ] for addr, jmp in patch_addr.items(): data[addr - base + bias:addr - base] = NOP * (abs (bias) // 2 ) print (f'Fill {hex (addr - base + bias)} to {hex (addr - base)} with NOP({abs (bias) // 2 } )' ) opcode = ks.asm(f'b {hex (jmp)} ' , addr + bias)[0 ] data[addr - base + bias:addr - base + bias + len (opcode)] = opcode print (f'Patched {hex (addr)} -> {hex (jmp)} ' ) fix_so = open ('fix.so' , 'wb' ) fix_so.write(data) fix_so.close()
修复前后:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void __fastcall sub_1700 (int a1, int a2, int a3) { int v3; char *v4; int v5; int v6; char v7; int v8; v4 = &v7; v3 = a3; v5 = a2; v6 = a1; v8 = 1066412143 ; __asm { MOV PC, R0; loc_174C } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 int __fastcall sub_1700 (int a1, int a2, int a3) { char *v3; char *v4; int v5; ... int v93; _BYTE *v94; v48 = &v52; v47 = a3; v49 = a2; v50 = a1; v54 = 1066412143 ; while ( 1 ) { ... } return _stack_chk_guard; }