如果早知道 学Angr也会被背刺…
同样作为模拟执行引擎 unicorn相比angr虽然没有内置的z3引擎 但是就使用体验上来说十分的易上手 再加上注册代码回调函数(hook)的功能用起来不可谓不舒服
模拟执行的准备工作
之所以说它易上手 是因为它的使用方法和keystone, capstone这两个汇编相关引擎很相似 指定一个框架和模式就能开始模拟执行了
以X86_64为例 模拟执行前需要创建unicorn.Uc对象
uc = Uc(UC_ARCH_X86, UC_MODE_64)
接下来就是进行内存映射 使用Uc.mem_map(addr, size)进行内存映射以获取存放代码和栈或者数据的字节的以映射内存 目前看来映射内存需要页对齐 否则会报错 保险起见一个页定在1mb(0x400 ** 2 byte)
PAGE = 0x400 ** 2
此后映射内存时addr和size最好都是n * PAGE的形式
unicorn的模拟执行不需要读取完整代码 只需要想要执行的代码片段被写入了对应的位置即可 但是为了方便也可以直接将二进制文件读到正确的内存上:
1
2
3
4
5
6
| CODE = 0
STACK= PAGE
uc.mem_map(CODE, PAGE)
uc.mem_map(STACK, PAGE)
uc.mem_write(CODE, open('.\\to_emu', 'rb').read())
uc.reg_write(UC_X86_REG_RSP, STACK + PAGE // 2)
|
栈基址可以随便定 而CODE需要保证读到的代码段字节在正确的位置上 最简单的方法就是打开IDA看程序基址 将CODE设为这个基址即可
unicorn中读写寄存器, 内存的方法也很简单 只用Uc.[mem|reg]_[read|write]()4个函数就可以完成 读写寄存器时可以直接用unicorn中准备好的宏定义标识要读写的寄存器 这些宏定义将一个组件名映射到一个整型上 格式都是UC_ARCH_TYPE_xxx
开始/结束模拟执行
unicorn中要开始和结束模拟执行也只由两个函数负责Uc.emu_[start|stop]() 开始模拟执行只需要指定开始执行的地址和结束地址
Hook/Unhook代码
uncorn提供了几种不同等级的hook 这里只介绍最通用的code hook
当注册了code hook后 和IDA下条件断点一样 在执行当前指令前会先执行我们的hook函数
添加Hook
使用hook_handle = Uc.hook_add(UC_HOOK_CODE, hook)来添加一个代码回调hook 函数返回一个回调函数句柄 在后续删除hook时要用到 多次添加hook不会覆盖掉前面的 而是链式调用各个hook
删除Hook
使用Uc.hook_add(hook_handle)来删除一个hook 要注意的是一个hook句柄只能在删除时使用一次 调用完后hook_handle就失效了 即使下次再添加同一个hook也不能用这个hook_handle来删除
保存/恢复上下文
不同于专门用于模拟程序执行的所有分支的angr 若unicorn在模拟执行前不手动设定各个通用寄存器的值就会默认为0 当遇到分支时不会像angr一样生成另一条stash 因此如果要用unicorn实现类似的功能就需要在遇到分支时手动保存上下文 然后对产生分支的寄存器或内存写入可能的值再从分支点开始进行模拟执行
相关的函数为:
1
2
| ctx = uc.context_save()
uc.context_restore(ctx)
|
unicorn的基本功能就结束了 下面是实战应用
实战
[b01lersCTF 2025] labyrinth
程序分析
程序实现了一个类似迷宫的函数 这个函数所在内存被mprotect设置为了rwx权限的 通过输入LUDR中的一个来进行移动 函数本体就是迷宫 根据输入会间接跳转到函数的其他地方:
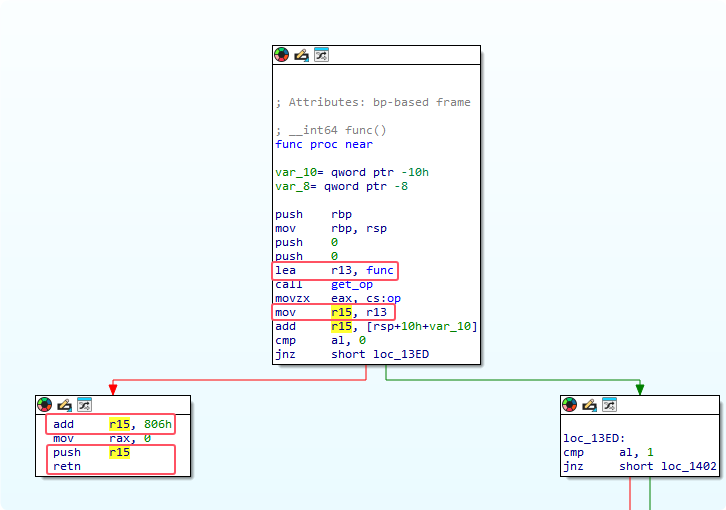
那么迷宫中每个节点的特征就很明显了 因为如果到达一个节点肯定要通过call来获取输入才能到达下一个 那么基本节点的特征就是call指令
直接看这种控制流来找到通往终点的路肯定是很难的 因为除了基本的根据输入来进行间接跳转 还有几个节点会修改函数本身导致某些节点对某些输入造成的跳转发生改变 这也是这个函数的内存被修改权限的原因:
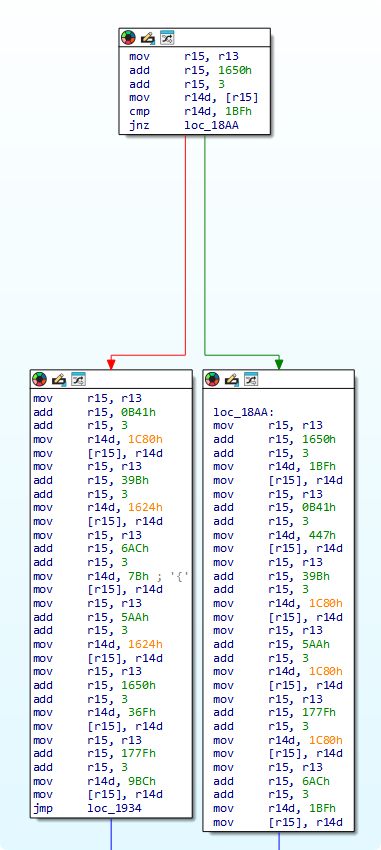
并且这些节点并不是经过一次改变了函数控制流后就不用关心的 后续还可能再经过并把函数的控制流修改回去 这样的节点有5个 手动记录一下位置
这个时候要获取清晰的各个节点之间的关系就是关键了 一开始我尝试patch程序将间接跳转修改为直接跳转 这样IDA就能成功反汇编查看伪代码了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| from idc import *
import idaapi
from keystone import *
ks = Ks(KS_ARCH_X86, KS_MODE_64)
base = 0
ea = func = 0x13b6 + base
end = 0x303A + base
indirect_jmp= [False, 0, 0]
nodes = []
def next_ins():
global ea
lenth = idaapi.decode_insn(idaapi.insn_t(), ea)
ea += lenth
def patch():
while ea <= end:
opcode = GetDisasm(ea).split()
if indirect_jmp[0] and opcode[0] == 'push' and opcode[1] == 'r15':
new_opcode = ks.asm(f'mov eax, {indirect_jmp[2]}')[0]
new_opcode+= ks.asm(f'jmp {func + indirect_jmp[1]}', ea - 2)[0]
new_opcode = bytes(new_opcode)
print(new_opcode, f'at {hex(ea - 7)}')
idaapi.patch_bytes(ea - 7, new_opcode)
indirect_jmp[0] = False
ea += 3
if len(opcode) == 3 and opcode[0] == 'add' and opcode[1] == 'r15,':
print(f'Found indirect jmp at: {hex(ea)}')
indirect_jmp[0] = True
try:
indirect_jmp[1] = int(opcode[2][:-1], 16)
except:
indirect_jmp[1] = 0
next_ins()
opcode = GetDisasm(ea).split()
indirect_jmp[2] = int(opcode[2])
next_ins()
patch()
|
确实能反汇编了 但是看起来还是很难绷:

虽然并不复杂但是跟给自己上了混淆一样 IDA也不会将其识别为switch-case结构
这时候就要请出我们的unicorn了 既然每个节点的特征明显 可以轻易获取 且每个节点只有4种输入 不妨在每个节点的入口进行模拟执行4种输入的结果 当模拟执行至其他节点时记录这两个节点间的关系
找到所有基本节点的关系后再在修改控制流的节点处进行模拟执行 直到下一个节点时保存上下文再对所有节点执行上面的流程 找出所有与先前不同的关系(实际上这一步也可以静态做 但是都unicorn了就要一u到底)
获取所有节点
这一步还是通过IDA进行
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| from idc import *
import idaapi
from keystone import *
ks = Ks(KS_ARCH_X86, KS_MODE_64)
base = 0
ea = func = 0x13b6 + base
end = 0x303A + base
indirect_jmp= [False, 0, 0]
nodes = []
def next_ins():
global ea
lenth = idaapi.decode_insn(idaapi.insn_t(), ea)
ea += lenth
def get_all_node():
while ea <= end:
opcode = GetDisasm(ea).split()
if opcode[0] == 'call':
nodes.append(ea)
next_ins()
get_all_node()
print(", ".join(hex(node) for node in nodes))
|
得到
1
2
3
| nodes = [
0x13c5, 0x1431, 0x149d, 0x1509, 0x1575, 0x15e1, 0x164d, 0x16b9, 0x1725, 0x1791, 0x1934, 0x19a0, 0x1a0c, 0x1a78, 0x1ae4, 0x1b50, 0x1bbc, 0x1c25, 0x1c91, 0x1cfd, 0x1d72, 0x1dde, 0x1e4a, 0x1eb6, 0x2225, 0x2291, 0x22fd, 0x2369, 0x27be, 0x282a, 0x2896, 0x2902, 0x296e, 0x29da, 0x2a46, 0x2ab2, 0x2b1e, 0x2c8c, 0x2fcd
]
|
获取节点间的关系
就和上面说的一样 需要先进行模拟前的上下文配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| from unicorn import *
from unicorn.x86_const import *
from capstone import *
cs = Cs(CS_ARCH_X86, CS_MODE_64)
uc = Uc(UC_ARCH_X86, UC_MODE_64)
PAGE = 0x400 ** 2
CODE = 0
STACK= PAGE
uc.mem_map(CODE, PAGE)
uc.mem_map(STACK, PAGE)
uc.mem_write(CODE, open('.\\labyrinth', 'rb').read())
uc.reg_write(UC_X86_REG_RSP, STACK + PAGE // 2)
start = 0x13B6
end = 0x303A
op = 0x6011
fail = 0x3036
success = 0x1D29
visited = set()
node_attrs = {}
node_sym = ''
node_op = ''
switcheron = ''
STOP = False
PRINT = False
switchers = [
0x17FD, 0x1F22, 0x23D5, 0x2B8A, 0x2CF8
]
nodes = [
0x13c5, 0x1431, 0x149d, 0x1509, 0x1575, 0x15e1, 0x164d, 0x16b9, 0x1725, 0x1791, 0x1934, 0x19a0, 0x1a0c, 0x1a78, 0x1ae4, 0x1b50, 0x1bbc, 0x1c25, 0x1c91, 0x1cfd, 0x1d72, 0x1dde, 0x1e4a, 0x1eb6, 0x2225, 0x2291, 0x22fd, 0x2369, 0x27be, 0x282a, 0x2896, 0x2902, 0x296e, 0x29da, 0x2a46, 0x2ab2, 0x2b1e, 0x2c8c, 0x2fcd
]
move = {
0 : 'L',
1 : 'D',
2 : 'U',
3 : 'R',
}
def hook0(uc : Uc, address, size, usr_data):
global STOP
if STOP:
STOP = False
uc.emu_stop()
code = uc.mem_read(address, size)
if code[0] == 0xE8:
uc.reg_write(UC_X86_REG_RIP, address + size)
STOP = True
hook0_handle = uc.hook_add(UC_HOOK_CODE, hook0)
uc.emu_start(CODE + start, end)
|
emu_stop无法终止模拟执行的bug
代码中的hook不直接让模拟执行在遇到call时就停止的原因是目前unicorn 2.0.1.post1有bug 如果在回调函数中修改了IP寄存器那么emu_stop()会失效 只能记录停止信号并在下一次进入hook 即执行下一条指令前退出
到这里为止就是让模拟执行来到第一个节点的位置的代码 此时就可以记录上下文进行对每个节点每种操作的模拟了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| def hook1(uc : Uc, address, size, usr_data):
global STOP
if STOP:
STOP = False
uc.emu_stop()
global visited, node_sym, node_op
if PRINT:
code = uc.mem_read(address, size)
dm = cs.disasm(code=code, offset=address)
for line in dm:
print(f"{hex(line.address)}\t{line.mnemonic} {line.op_str} R14D:{hex(uc.reg_read(UC_X86_REG_R14D))} R15:{hex(uc.reg_read(UC_X86_REG_R15))}", end='')
print()
if address in nodes:
visited.add((node_sym, hex(address)[2:], node_op))
uc.reg_write(UC_X86_REG_RIP, address + size)
STOP = True
elif address in switchers and not node_sym.startswith('S'):
visited.add((node_sym, f"S{switchers.index(address)}", node_op))
STOP = True
elif address == success:
visited.add((node_sym, 'win', node_op))
STOP = True
elif address == fail:
STOP = True
return
uc.hook_del(hook0_handle)
hook1_handle = uc.hook_add(UC_HOOK_CODE, hook1)
ctx = uc.context_save()
for node in nodes:
node_sym = hex(node)[2:]
for o in range(4):
node_op = move[o]
uc.context_restore(ctx)
uc.reg_write(UC_X86_REG_RIP, CODE + node + 0xC)
uc.reg_write(UC_X86_REG_EAX, o)
uc.emu_start(CODE + node + 0xC, end)
|
至此visited中就保存了所有节点在没有经过任何一个开关时的连接状态 后续就是模拟各个开关打开后节点间的状态 hook的实现和hook1基本相同 只不过要排除掉原本就存在的节点关系:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
| def hook2(uc : Uc, address, size, usr_data):
global STOP
if STOP:
STOP = False
uc.emu_stop()
global visited, node_sym, node_op
if PRINT:
code = uc.mem_read(address, size)
dm = cs.disasm(code=code, offset=address)
for line in dm:
print(f"{hex(line.address)}\t{line.mnemonic} {line.op_str} R14D:{hex(uc.reg_read(UC_X86_REG_R14D))} R15:{hex(uc.reg_read(UC_X86_REG_R15))}", end='')
print()
if address in nodes:
uc.reg_write(UC_X86_REG_RIP, address + size)
if (node_sym, hex(address)[2:], node_op) not in visited:
visited.add((node_sym, hex(address)[2:], f'{switcheron}-{node_op}'))
STOP = True
elif address in switchers and not node_sym.startswith('S'):
if (node_sym, f"S{switchers.index(address)}", f'{node_op}') not in visited:
visited.add((node_sym, f"S{switchers.index(address)}", f'{switcheron}-{node_op}'))
STOP = True
elif address == success:
if (node_sym, 'win', node_op) not in visited:
visited.add((node_sym, 'win', f'{switcheron}-{node_op}'))
STOP = True
elif address == fail:
STOP = True
hook2_handle = None
for idx in range(len(switchers)):
if hook2_handle:
uc.hook_del(hook2_handle)
hook1_handle = uc.hook_add(UC_HOOK_CODE, hook1)
node_sym = f"S{idx}"
switcheron = f'S{idx}'
node_op = '-'
uc.context_restore(ctx)
uc.reg_write(UC_X86_REG_RIP, CODE + switchers[idx])
uc.mem_write(CODE, open('.\\labyrinth', 'rb').read())
uc.emu_start(CODE + switchers[idx], end)
uc.hook_del(hook1_handle)
hook2_handle = uc.hook_add(UC_HOOK_CODE, hook2)
uc.mem_write(STACK, b'\x00' * PAGE)
new_ctx = uc.context_save()
for node in nodes:
node_sym = hex(node)[2:]
for o in range(4):
node_op = move[o]
uc.context_restore(new_ctx)
uc.reg_write(UC_X86_REG_RIP, CODE + node + 0xC)
uc.reg_write(UC_X86_REG_EAX, o)
uc.emu_start(CODE + node + 0xC, end)
|
后面还用networkx画出了图 但是因为节点和边太多看起来还是很抽象 而且写完的时候发现大哥已经出了(