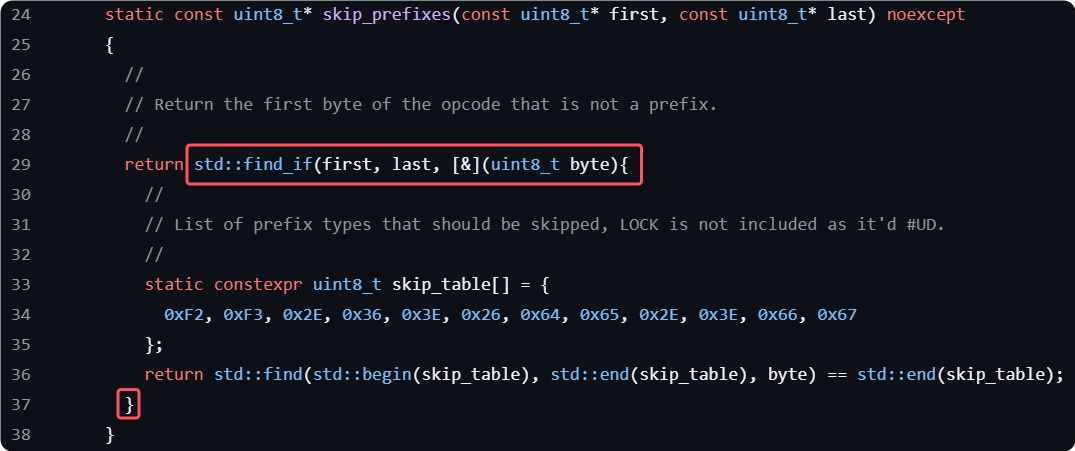
staticconstuint8_t* skip_prefixes(constuint8_t* first, constuint8_t* last)noexcept { // // Return the first byte of the opcode that is not a prefix. // return std::find_if(first, last, [&](uint8_t byte) { // // List of prefix types that should be skipped, LOCK is not included as it'd #UD. // staticconstexpruint8_t skip_table[] = { 0xF2, 0xF3, 0x2E, 0x36, 0x3E, 0x26, 0x64, 0x65, 0x2E, 0x3E, 0x66, 0x67 }; bool is_prefix = false; for (constauto& prefix_byte : skip_table) { if (prefix_byte == byte) { is_prefix = true; break; } } return !is_prefix; //return std::find(std::begin(skip_table), std::end(skip_table), byte) == std::end(skip_table); }); }
// // Split the 2MB page where the code we want to hook resides. // vp.ept().split_2mb_to_4kb(data.page_exec & ept_pd_t::mask, data.page_exec & ept_pd_t::mask);
// // Set execute-only access on the page we want to hook. // vp.ept().map_4kb(data.page_exec, data.page_exec, epte_t::access_type::execute);
// // We've changed EPT structure - mappings derived from EPT need to be // invalidated. // vmx::invept_single_context(vp.ept().ept_pointer()); break;
case0xc2: hvpp_trace("vmcall (unhook)");
// // Merge the 4kb pages back to the original 2MB large page. // Note that this will also automatically set the access // rights to read_write_execute. // vp.ept().join_4kb_to_2mb(data.page_exec & ept_pd_t::mask, data.page_exec & ept_pd_t::mask);
// // We've changed EPT structure - mappings derived from EPT // need to be invalidated. // vmx::invept_single_context(vp.ept().ept_pointer()); break;
voidvmexit_custom_handler::handle_ept_violation(vcpu_t& vp)noexcept { auto exit_qualification = vp.exit_qualification().ept_violation; auto guest_pa = vp.exit_guest_physical_address(); auto guest_va = vp.exit_guest_linear_address();
auto& data = user_data(vp);
if (exit_qualification.data_read || exit_qualification.data_write) { // // Someone requested read or write access to the guest_pa, // but the page has execute-only access. Map the page with // the "data.page_read" we've saved before in the VMCALL // handler and set the access to RW. // hvpp_trace("data_read LA: 0x%p PA: 0x%p", guest_va.value(), guest_pa.value());
vp.ept().map_4kb(data.page_exec, data.page_read, epte_t::access_type::read_write); } elseif (exit_qualification.data_execute) { // // Someone requested execute access to the guest_pa, but // the page has only read-write access. Map the page with // the "data.page_execute" we've saved before in the VMCALL // handler and set the access to execute-only. // hvpp_trace("data_execute LA: 0x%p PA: 0x%p", guest_va.value(), guest_pa.value());
// // An EPT violation invalidates any guest-physical mappings // (associated with the current EP4TA) that would be used to // translate the guest-physical address that caused the EPT // violation. If that guest-physical address was the translation // of a linear address, the EPT violation also invalidates // any combined mappings for that linear address associated // with the current PCID, the current VPID and the current EP4TA. // (ref: Vol3C[28.3.3.1(Operations that Invalidate Cached Mappings)]) // // // TL;DR: // We don't need to call INVEPT (nor INVVPID) here, because // CPU invalidates mappings for the accessed linear address // for us. // // Note1: // In the paragraph above, "EP4TA" is the value of bits // 51:12 of EPTP. These 40 bits contain the address of // the EPT-PML4-table (the notation EP4TA refers to those // 40 bits). // // Note2: // If we would change any other EPT structure, INVEPT or // INVVPID might be needed. //
// // Make the instruction which fetched the memory to be executed // again (this time without EPT violation). // vp.suppress_rip_adjust(); }
if (DeviceHandle == INVALID_HANDLE_VALUE) { printf("Error while opening 'hvpp' device!\n"); return; }
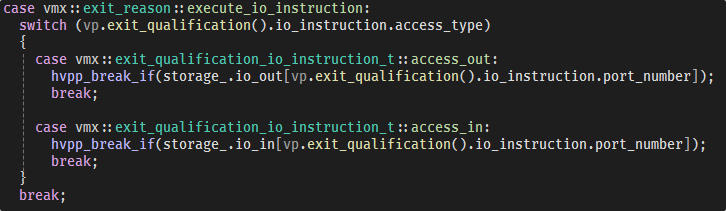
// // Issue IOCTL call to the driver. // When kernel debugger is attached, this IOCTL will instruct // the hypervisor to set one-time breakpoint when IN/OUT // instruction from/to port 0x64 (keyboard I/O port) is executed. // // See hvpp/device_custom.cpp. //
// // Return value should be 0x1337 if the kernel debugger // is attached, 0xCAFE otherwise. // printf("IOCTL return value: 0x%04x (size: %u)\n", IoPort, BytesReturned); }
if (!buffer || buffer_size < ioctl_enable_io_debugbreak_t::size) { returnmake_error_code_t(std::errc::invalid_argument); }
// // Capture the I/O port from the buffer. // uint16_t& io_port = *((uint16_t*)buffer);
// // Do nothing if kernel debugger is not attached. // if (!debugger::is_enabled()) { // // Set value of the output buffer (example). // io_port = 0xCAFE; return {}; }